Query Service 성능 개선기 두 번째 이야기
두 번째 Query Service 성능 개선기를 작성하게 되었다. 첫 번째에서 문제가 다 해결된게 아니냐 싶을 수도 있지만 슬프게도 다 해결된 것은 아니었다.
여전히 DB의 사용률에 따라 조회 시간의 차이가 롤러코스터급으로 들쭉날쭉 했고 이를 반드시 해결해야 서비스 릴리즈를 할 수 있었다. 또한 DB에 엄청난 속도로 데이터가 쌓이고 있었기 때문에 이런 상황에도 전혀 무관하게 일정한 조회 시간을 유지해야 했다.
어떤 Query Service이고 이 서비스가 어떤 컨텍스트에서 어떤 서비스를 제공하는지는 첫 번째 이야기에서 살펴볼 수 있다.
첫 번째 이야기가 끝나갈 즈음에 하드웨어와 같은 물리적인 것들에 대해 언급을 했는데 두 번째 이야기에서는 이 쪽을 좀 더 얘기해보려고 한다. 실제로 Query Service와 DB의 물리적인 거리가 성능에 엄청난 영향을 주었기 때문이다. 그리고 소프트웨어적으로 문제가 여전히 남아있었는데 이를 어떻게 해결하였지에 대해 해결하였는지 포스팅을 해보려고 한다.
원(Source) 테이블은 웬만하면 가공을해서 건드리자
여기서 '가공'은 다양한 방법이 있을 수 있다. Source 테이블 중에 필요한 데이터들에 대해서만 캐싱을 하는 테이블을 만들던지 다른 방법이 있을 수 있다. 말하고 싶은 것은 웬만하면 SELECT * FROM Entity와 같이 어떠한 가공을 하지않고 '그대로' 가지고 오는 것은 삼가자는 것이다.
이전의 쿼리들은 다음과 같은 형태였다.
어떤 테이블 한 페이지에 대한 아이템들을 가져올 때
SELECT ...
FROM Message AS m, Event AS e
WHERE ...
ORDER BY m."number" DESC
LIMIT 25사용자가 테이블에서 아이템을 필터링하고 싶을 때, 사용자가 선택가능한 필터링 키를 가져올 때
SELECT ...
FROM Message AS m
WHERE ...
GROUP BY m."status"두 쿼리 모두 테이블 전체를 살펴서 조건에 맞는 결과물을 돌려준다. 생각해보면 큰 문제를 가진 쿼리들이다. 지속적으로 데이터가 늘어나는 상황을 전혀 고려하지 않았기 때문이다. 시간이 지나면 지날수록 원하는 데이터들을 가져오는 시간이 증가할 것이고 이는 곧 사용자의 불편함으로 이어진다. 소프트웨어의 품질이 떨어진다.
테이블 전체를 살펴보는 이상 쿼리를 바꿈으로써 개선되는 차이가, 살펴보는 테이블의 row를 줄일 때 개선되는 차이보다 크지 않다.
서비스 기획팀과 논의를 거친 후에 테이블에 전체 아이템을 보여주는 것이 아니라, 최근 메세지 25000개에 대해 보여주기로 결정했다. 그렇다면 이제 테이블 전체를 살펴보는 것이 아니라 최근 25000개에 대해서만 살펴보면 된다.
이 때 단순히 쿼리 마지막에 LIMIT 25000 을 붙이는 것이 아니라 FROM 에서 이미 25000개의 메세지가 선택되어있어야 한다.
떠오른 방법이 두 가지가 있었고 두 가지 아이디어는 다음과 같다.
WITH을 이용하여 임시 테이블을 만들어 놓고 해당 테이블을 이용하여 쿼리를 수행하는 것
WITH m AS (
SELECT *
FROM public."Message" AS mm
WHERE mm."id" = '...'
LIMIT 25000
ORDER BY mm."number" DESC
)
SELECT ...
FROM m
WHERE ...단순하게 subquery를 이용하여 FROM에 25000개의 메세지를 뽑는 것
SELECT ...
FROM (
SELECT *
FROM public."Message" AS mm
WHERE mm."id" = '...'
LIMIT 25000
ORDER BY mm."number" DESC
)
WHERE ...분석기를 돌려본 결과 subquery를 만드는 것이 미세하게 빨랐고 (정확한 원인은 좀 더 리서치가 필요하지만 간이 테이블을 만드는데 좀 더 코스트가 드는 것이 아닐까라고 생각했다.) subquery를 이용한 방법을 택했다.
Subquery를 이용했을 때 Message를 조회하는데 걸리는 시간 측정
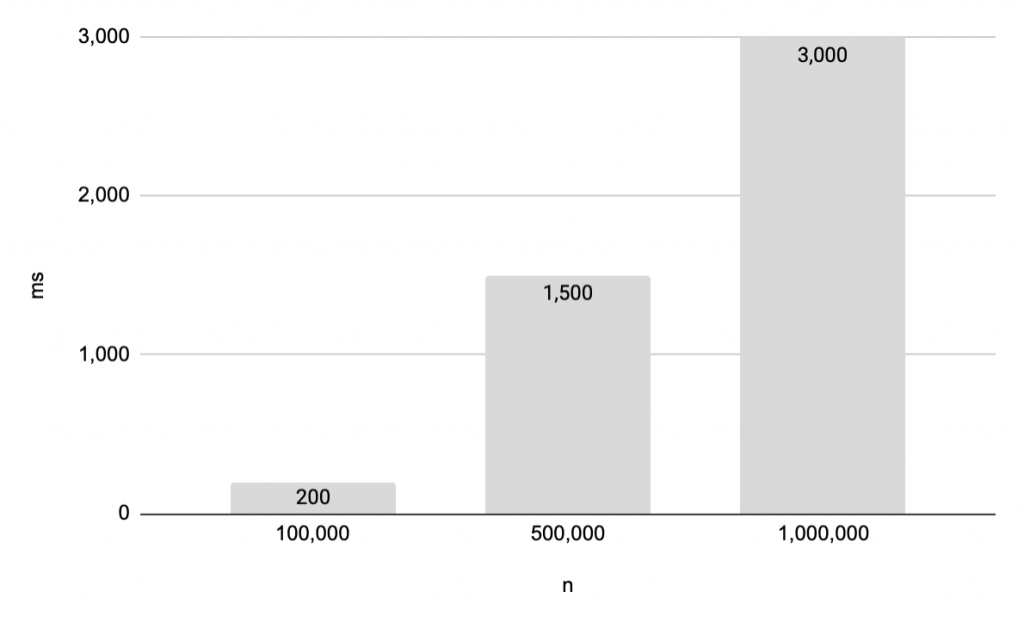
실제로는 25000개에 대해서만 측정하면 되지만 궁금해서 Message를 증가시키면서 시간을 측정해보았다. 그래프가 단조 증가하는 형태를 보이면서 50만개 부터는 1초가 넘는 시간이 걸리기 때문에 무시할 수 없는 수준이었다.
Latency를 무시하지 말자
위에서 언급했던 문제는 소프트웨어적인 문제라 한다면 이번 단락에서는 하드웨어적인 혹은 물리적인 어떤 것이 성능 문제에 꽤 큰 영향을 줬는데 그것이 바로 지리적 거리에 의한 latency이다.
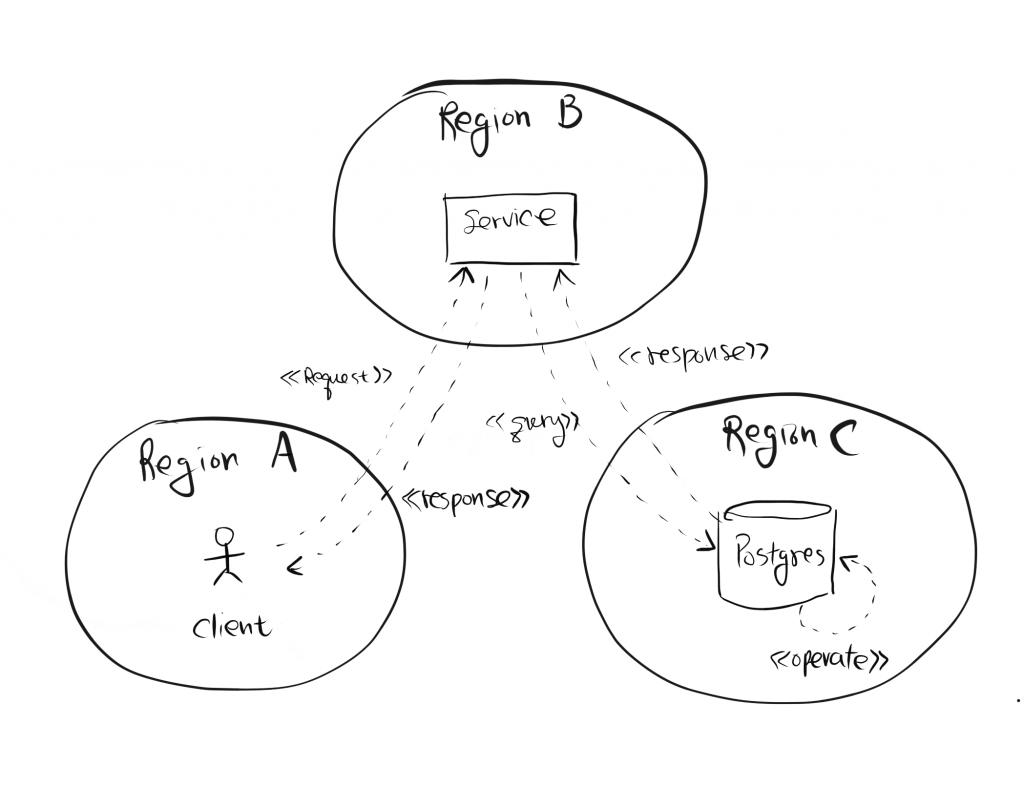
이번 성능 저하의 큰 원인 중 하나를 꼽자면 Service와 DB가 멀리 떨어진 다른 region에 있었다는 것이다. 멀리 떨어진 region에 존재하다보니 Database가 내부적으로 결과물을 조회하는 operate에 걸린 시간보다 Service와 Database 사이에서 요청과 응답을 주고받는 시간이 더 컸다. (Client와 Service 사이에 걸리는 latency는 상대적으로 무시할만 하다.)
Service가 한 번 쿼리하는데도 latency가 더 큰데 하나의 API 안에서 순차적으로 Database를 여러 번 쿼리하는 경우에는 그 차이가 더 심하다.
이번 문제의 해결은 Service와 Database를 같은 region에 둠으로써 문제를 해결했다. 문제를 해결하기 위해서 서비스를 잠시 중단해야했다.
ORDER BY의 대상이 되는 필드에 index를 걸자
Database의 성능을 높이고 Service의 region 마이그레이션을 마쳤지만 여전히 API 하나가 느리게 돈다. 어디가 문제인지 살펴보니 아까 위에서 살펴본 쿼리가 여전히 말썽이었다.
SELECT ...
FROM (
SELECT *
FROM public."Message" AS mm
WHERE mm."id" = '...'
LIMIT 25000
ORDER BY mm."number" DESC
)
WHERE ...Message 테이블에 number 필드에 인덱스가 걸려있지 않은 것을 보고 ORDER BY가 문제일 수도 있겠다라는 생각이 들어 리서치를 해보니 Postgres에서 sorting을 할 때 index를 활용한다고 명시되어있었다.
In addition to simply finding the rows to be returned by a query, an index may be able to deliver them in a specific sorted order. This allows a query's
ORDER BYspecification to be honored without a separate sorting step. Of the index types currently supported by PostgreSQL, only B-tree can produce sorted output
소팅 대상이 되는 필드에 인덱스를 걸고 안걸고에는 어떤 차이가 있을까?
문제의 대상이 되는 다음 쿼리만을 이용해 분석기를 돌려보았다.
SELECT *
FROM public."Message" AS mm
WHERE mm."id" = '...'
LIMIT 25000
ORDER BY mm."number" DESCnumber에 인덱스가 걸려있지 않은 경우
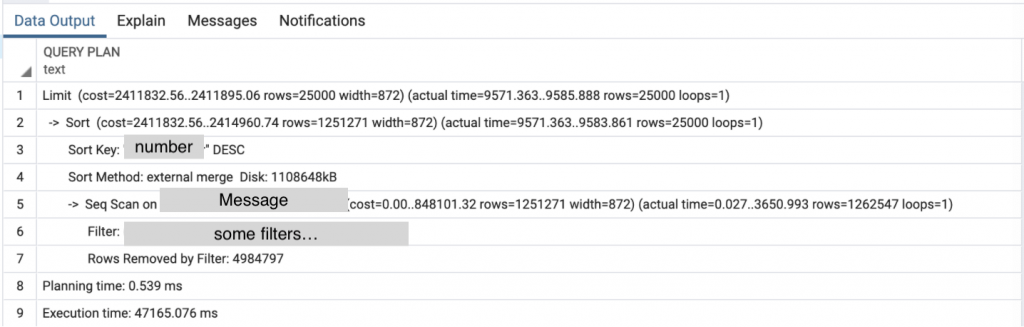
number에 인덱스가 걸려있는 경우
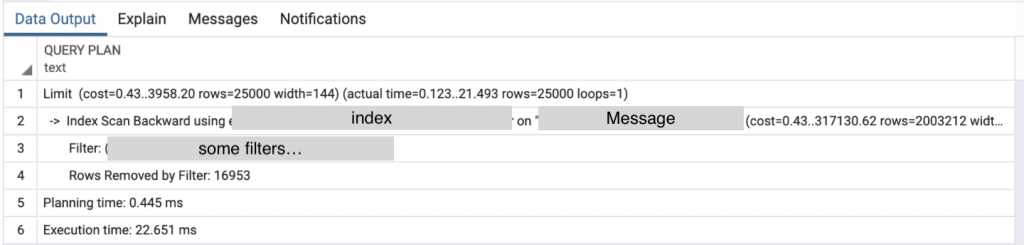
주목해야할 부분은 '인덱스가 걸려있지 않은 경우'의 5번째 줄과 '인덱스가 걸려있는 경우'의 2번째 줄이다. 인덱스가 걸려있지 않은 경우에는 sequential scan 즉 일일히 돌면서 sorting을 하는 반면에 인덱스가 걸려있는 경우엔 index scan을 이용하여 sorting을 수행한다.
최종적으로 걸리는 Execution time을 비교해보았을 때 둘의 성능차이는 약 2000배가 차이난다.
정리

성능 개선 이야기는 여기까지이다. 첫 번째 이야기와 두 번째 이야기에서 성능과 관련해서 어떻게 문제를 해결했는지 정리해보면 다음과 같다.
JPA에서 FK로 관계를 가진 두 엔티티를 가지고 오려고할 때 1+N 이슈가 발생할 수 있다.
이것을 간단히 JPA에서 제공하는 Fetch 방법을 변경하여 고칠 수도 있지만 그렇지 않을 때도 있었다. 이번에는 NativeQuery를 이용하여 필요한 쿼리를 만들었다.
쿼리 분석기를 가까이 하자.
SQL 튜닝과 관련하여 깊은 지식이 없었던 필자는 EXPLAIN ANALYZE 와 같은 분석기를 통해 어떤 구문이 문제가 되는지 어떤 쿼리가 더 성능이 좋은지, 혹은 어떤 것은 바꿔도 전혀 상관이 없다는 것을 파악할 수 있었다. SQL 구문의 단계마다 어떤 식으로 동작하고 각 단계의 cost를 볼 수 있어서 EXPLAIN ANALYZE 가 이번 성능 이슈를 해결하는데 듬직한 도구가 되었다.
하드웨어 혹은 그 밖의 물리적인 어떤 것이 성능 이슈와 직접적으로 연관되었을 수 있다.
실제로 Database의 성능은 매우 중요하다. 어느정도 성능이 보장되어야 만족할만한 쿼리 속도가 나온다. 그리고 latency도 치명적인 원인일 수 있다. 특히 db와 db를 이용하는 서비스가 멀리 떨어져있으면 문제가 될 수 있다.