Create New SmartContract Programming Language with Go — Lexer part
This is the second post about project which creates new smart contract language with go. In the last post, introduced about project concept, why we decided to built new smart contract language and brief architecture. The project is WIP and open source so you can visit github and feel free to contribute to our project.
- Prev Post: New language concept, purpose, architecture
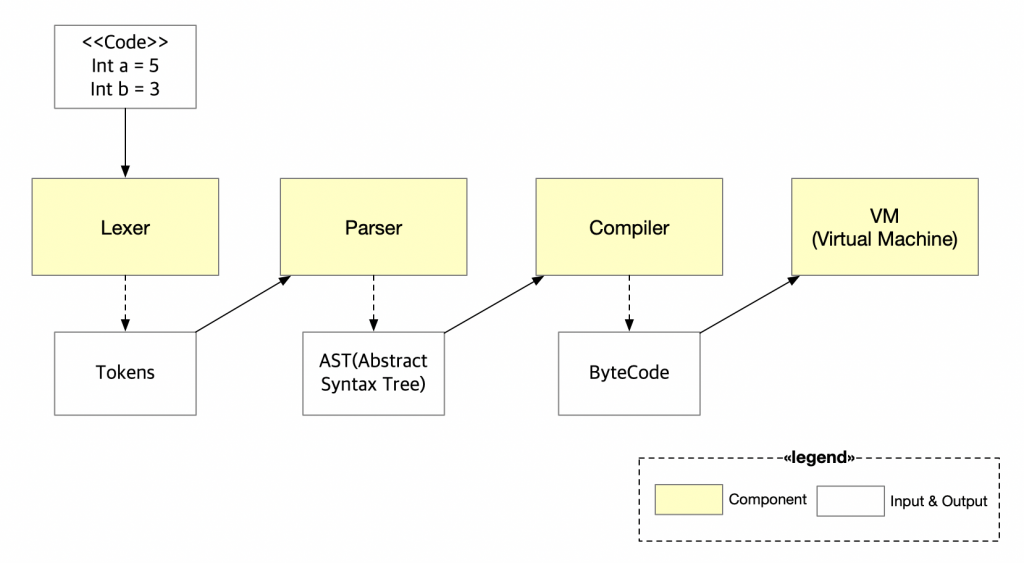
Project consists of four components: Lexer, Parser, Compiler, VM. And in this post we’re deeply talking about first component; Lexer.
Lexer?
Before we move on to code, what is a lexer? Lexer literally do lexical analysis for given input text. Then how lexical analysis proceed? First lexer reads the stream of characters which consist of source code written by programming language syntax one by one, then whenever lexer meets meaningful permutation called lexeme from characters, make that lexeme as token and keep doing same things until we meet eof
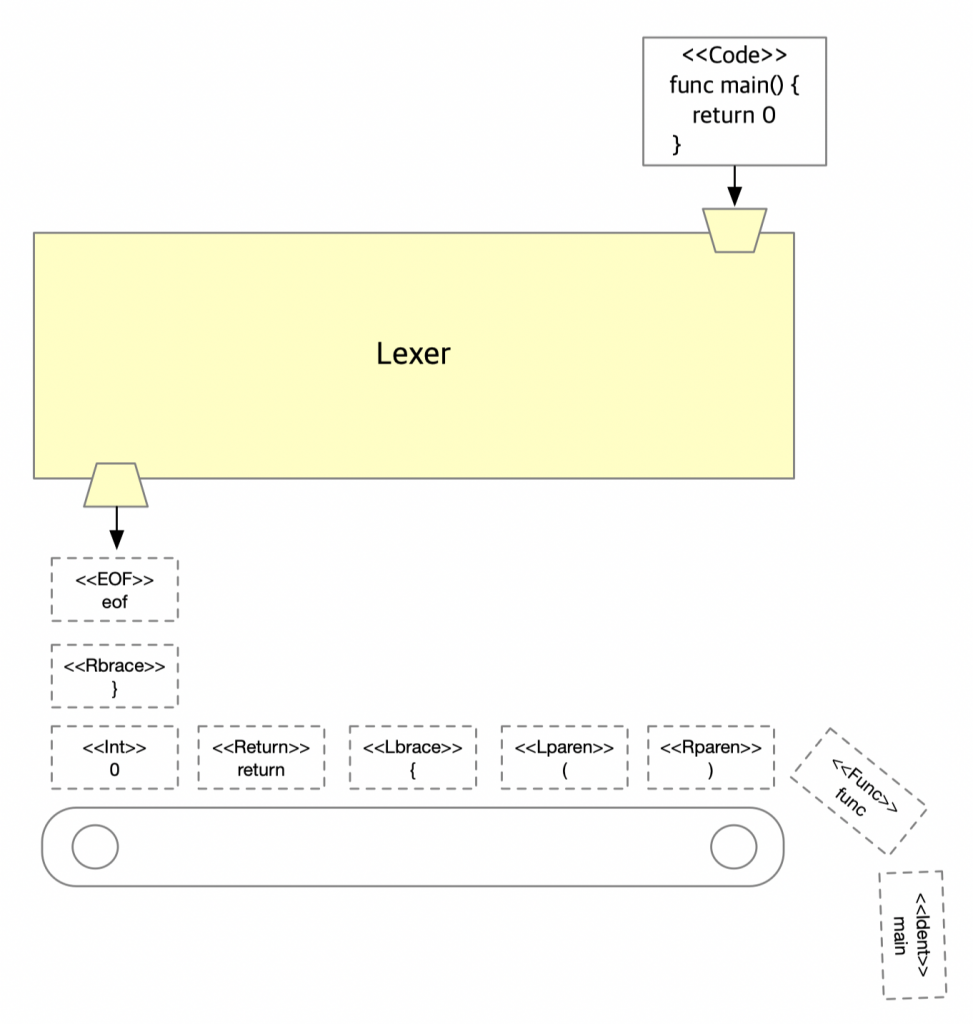
For example, in the diagram lexer take the source code; ‘func main() { return 0 }’, then lexer reads code character by character; ‘f’, ‘u’, ‘n’, ‘c’. At the time lexer read ‘c’ lexer knows ‘fun’ + ‘c’ is meaningful word, keyword for function, then lexer cut ‘func’ characters from text(code) and make token for that word. Lexer keep this work until we meet eof . In a nutshell lexer group characters and make tokens.
Token?
Yes lexer makes tokens… and… what is token? We can see ‘func’ word as raw data, but without processing that data, those data cannot be easily used from other components. And token is doing that job for us, token is data structure which helps data to be expressed structurally.
type TokenType int
type Token struct {
Type TokenType
Val string
Column Pos
Line int
}That’s our token defined in project. Type is type for word, Val for word value. With this Token structure the other components like parser can do its job more efficiently and code will be much maintainable and scalable.
How to tokenize?
State, Action
Our lexer design is greatly inspired by golang template package which use state and action concept. Actually go-ethereum also use this concept.
- State represents where the lexer is from the given input text and what we expect to see next.
- Action represents what we are going to do in current state with a piece of input
We can see lexer jobs — read character, generate token, move on to next character— as take the action with current state and move on to next state. After each action, you know where you want to be, the new state is the result of the action.
State function
// stateFn determines how to scan the current state.
// stateFn also returns the stateFn to be scanned next after scanning the current state.
type stateFn func(*state, emitter) stateFnThis is our state function declaration. State function take current state and emitter, return another state function. Returned state function is based on the current state and knows what to do next. I know that state function definition is quite recursive but this helps keep things simple and clear
// emitter is the interface to emit the token to the client(parser).
type emitter interface {
emit(t Token)
}And you may have curiosity, what does emitter do for us. You may have noticed that we know how to lexing the given inputs, but don’t know how to pass the generated tokens to the client which is probably something like parser. This is why we need emitter , emitter simply pass the token to the client using one of go features, channel. We are going to see how emitter works in a few seconds.
Run our state machine
// run runs the state machine for the lexer.
func (l *Lexer) run(input string) {
state := &state{
input: input,
}
for stateFn := defaultStateFn; stateFn != nil; {
stateFn = stateFn(state, l)
}
close(l.tokench)
}This is our lexer run method which takes the input string — source code — and make state with our input. And in the for-loop state function call with the state as argument then return value of state function and this is the new state function. We can see lexer is passed to the state function as emitter , don’t be nervous we see this later how lexer implements emitte interface. From now, we just need to keep it mind how our state machine works:
take the current state, do action, walk over to next state.
What is the advantage of doing this? Well, first of all, we don’t have to check everytime what state we are in. That’s not our concern. We are always in the right place. The only thing to do in our machine is just run state function until we meet nil state function.
Run our machine concurrently
We don’t talk much about how to emit the token we generate to the client and I think this is the right time. The idea is we are going to run the lexer as a go routine with the client probably like parser so the two independent machines do their jobs, whenever the lexer has a new thing the client will lob it and do their own work. This mechanism can be done by go channel.
Channel is one of the greatest features in go language and yes complex, but in our lexer it is just a way to deliver data over to another program which may be running completely independent.
type Lexer struct {
tokench chan Token
}
func NewLexer(input string) *Lexer {
l := &Lexer{
tokench: make(chan Token, 2),
}
go l.run(input)
return l
}
// emit passes an token back to the client.
func (l *Lexer) emit(t Token) {
l.tokench <- t
}That’s our lexer definition it has just token channel which are going to be used when emitting token to the client. And we can see in NewLexer start to run machine using go-routine. How to receive these tokens is not covered in this post because this is lexer component and will be covered in the next post, parser part.
How state function can be implemented?
We’ve seen the big picture of how our lexer structured and let’s get into deeper: What does state function looks like?
func defaultStateFn(s *state, e emitter) stateFn {
switch ch := s.next(); {
case ch == '!':
if s.peek() == '=' {
s.next()
e.emit(s.cut(NOT_EQ))
} else {
e.emit(s.cut(Bang))
}
...
case ch == '+':
e.emit(s.cut(Plus))
...
case unicode.IsDigit(ch):
s.backup()
return numberStateFn
...
default:
e.emit(s.cut(Illegal))
}
return defaultStateFn
}I brought defaultStateFn , because this function has all the idea how state function works. First walk to the next character from the state using next(). Remember? state has input text. Then depending on the character we decide how to handle that. There are lots of cases but I skipped and brought 4 cases because other cases have same idea for one of those.
case ch == '!':
if s.peek() == '=' {
s.next()
e.emit(s.cut(NOT_EQ))
} else {
e.emit(s.cut(Bang))
}Let’s assume that the character we read is ‘!’. But only with ‘!’, we cannot generate token. Why? because we don’t know yet whether ‘!’ is sole ‘!’ or ‘!’ is part of the ‘!=’ not equal sign. So how can we know that? We should read one character from state, but be careful as you can see the code we do not next but peek. Why do not just next? Because in the case ‘!’ character is just bang mark, there’s no way to go back. — Yes I know, we have backup function which steps back one rune, we can implement in different way but I think it is style issue. After reading characters cut the characters we’ve read in the current state and generate token then emit.
case ch == '+':
e.emit(s.cut(Plus))In the case of ‘+’, plus character. It is much simple because there’s no other option to read differently — We do not yet have ++ like operator — so just cut and emit that return default state function.
case unicode.IsDigit(ch):
s.backup()
return numberStateFnWhat if the next character is digit? Then we should go back. Why? Because if the read character is digit, we should take different action which opts for digit but we are in the wrong way, default state function so go step back one characters and by returning numberStateFn which lex digit characters, we can handle digit character properly.
default:
e.emit(s.cut(Illegal))And if the read character is not defined in our cases, what should we do? Panic? Print out error message? No we designed in the case of when lexer meet not defined character, generate Illegal token and keep on working.
Why we designed like this? well, we thought that error handling is not part of lexer, so pass over the responsibility to others who receive tokens. By doing this, we can keep simple, there’s no error handling code so more readable, keep focus on its work.
That’s it! We’ve seen how state function basically works. In the case of read character is not sufficient to make token then read one more, if sufficient then generate token and emit. In the case character should be dealt with differently then step back and handle it with different state function which opts for that character. What if character is not defined in our set, than generate illegal token and move on.
Conclusion
So in this post we’ve seen how lexer can be designed and work. We used state and action to lexical analysis the given input string. Take the action with its state and move on to next state. By doing this we can our state machine keep simple and scalable.
Plus, run our state machine concurrently with go routine. So lexer can run independent with its client and whenever client needs token from the lexer, client can take generated token from the channel pushed by emitter.
In the next post, we’ll cover about parser which receive tokens from lexer and do its own work :)