HoneyBadgerBFT Protocol에 대해서
이 글은 BFT 기반 합의 알고리즘 중에 하나인 HoneyBadgerBFT에 대해서 어떤 특징을 가지고 어떤 식으로 동작하는지 설명하고자 한다.
과거에서부터 지속적인 오퍼레이션이 중요한 어플리케이션들은 BFT 계열의 프로토콜을 도입하여 fault-tolerant한 시스템을 만들고자 하였다. 분산 시스템에 대한 관심이 높아지면서 어떤 노드 혹은 컴포넌트가 제대로 동작하지 않는지 시스템 내부적으로 확인할 수 있는 failure-detection과 시스템 내부에서 어떤 컴포넌트가 제대로 동작하지 않더라도 전체 시스템 입장에서는 여전히 정상적으로 동작할 수 있도록 도와주는 fault-tolerant 프로토콜의 중요성이 커졌다. 블록체인 또한 잠깐이라도 시스템이 멈춘다면 네트워크에 참여한 구성원들에게 경제적인 피해를 줄 수 있으므로 지속적인 운용이 매우 중요하다고 할 수 있다.
현재 BFT 계열의 합의 알고리즘을 사용하고 있는 블록체인을 살펴보면 대부분 partial synchrony 한 특징을 가지고 있는 PBFT를 그대로 쓰거나 PBFT를 베이스로 각자 도메인에 맞게 변형해서 쓰고 있다.
Partial Synchrony
HoneyBadgerBFT 프로토콜에 대해서 설명하기 전에 현재 존재하는 BFT 시스템 중 대부분은 partial synchronous 하다. partial synchronous 하다는 것은 어떤 의미일까?
Partial synchronous한 시스템을 가운데에 두고 양 극에는 synchronous한 시스템과 asynchronous한 시스템이 있다. synchronous 하다는 것은 정해진 𝚫 만큼의 시간 상한선이 있어 컴포넌트 혹은 노드간에 메세지 전달이 𝚫 시간 이내로 이뤄져야하는 시스템을 말하고, 𝚫 시간 상한선 안 쪽으로 메세지가 전달되지 못하면 이는 예외적인 상황으로 시스템 각자에 맞는 핸들링이 필요하다. 다시 말해 Partial synchronous한 시스템은 𝚫 만큼의 시간에 대해 time assumption을 가지고 있다는 것을 말한다. asynchronous 하다는 것은 반대로 𝚫 시간 상한선이 존재하지 않고 언제든 메세지가 도착하기만 하면 동작하는 시스템을 말한다. Partial synchronous한 경우는 간단히 말하면 𝚫 만큼의 시간 상한선이 존재하지만 그것이 고정적이지 않고 상황에 따라 𝚫 값이 변하는 시스템을 말한다. 따라서 asynchronous한 시스템에서는 time assumption이 존재하지 않는다.
그런데 partial synchronous한 BFT 시스템에는 대표적인 몇 가지 문제점이 존재한다.
첫 번째로 만약에 악의적인 노드가 메세지를 주고받을 때 지속적으로 𝚫 시간 상한선을 초과하는 경우 시스템의 liveness를 보장할 수 없고 더 이상 BFT 프로토콜이 진행되지 않을 수 있다.
두 번째로 합의에 참여하고 있는 노드들이 모두 정상적으로 동작하고 있다하더라도 네트워크가 불안정한 경우 throughput이 급격히 줄어들 수 있다. 예를 들어 특정 순간 네트워크가 간헐적으로 불안정해지는 경우가 있을 것이다. 이 때 partial synchronous BFT는 timeout이 발생하여 새로운 리더를 선출할 것이며 어떤 BFT는 이에 더불어 다시 timeout이 나는 상황을 방지하기 위해서 timeout 시간을 증가시킬 수도 있다. 이상적으로 네트워크 환경이 불안정할 때 우리가 기대할 수 있는 최상의 throughput은 네트워크 현재 제공할 수 있는 대역폭을 그대로 가져가는 것이다. 하지만 위와 같은 상황에서는 일단 리더를 선출하는 동안 프로토콜이 진행되지 않을 것이며 timeout 간격을 증가시킨 경우에는 네트워크가 일시적으로 불안정하거나 끊긴 경우 새로운 리더를 뽑기 까지 더 많은 시간을 기다려야할 것이다. 이처럼 partial synchronous BFT에서는 주어진 네트워크 환경을 최대한 활용할 수 없다는 문제점이 있다.
The First Practical Asynchronous BFT Protocol
HoneyBadgerBFT는 이러한 partial synchronous BFT의 문제점을 극복하고자 고안되었고 liveness와 safety를 동시에 보장하는 최초의 실용적인 liveness와 safety를 보장하는 asynchronous deterministic BFT 프로토콜이라고 논문에서 소개되고 있다.
이는 1985년에 소개된 FLP 논문에서 언급한 ‘asynchronous deterministic protocol은 불가능하다’는 말과 상반되며 논문의 abstract는 다음과 같다.
In this paper, we show the surprising result that no completely asynchronous consensus protocol can tolerate even a single unannounced process death. We do not consider Byzantine failures, and we assume that the message system is reliable- it delivers all messages correctly and exactly once. Nevertheless, even with these assumptions, the stopping of a single process at an inopportune time can cause any distributed commit protocol to fail to reach agreement. Thus, this important problem has no robust solution without further assumptions about the computing environment or still greater restrictions on the kind of failures to be tolerated!
그렇다면 HoneyBadgerBFT는 어떤 특징을 가지고 있을까?
Asynchrony
Partial synchronous한 BFT의 가장 대표적인 예인 PBFT와 HoneyBadgerBFT를 비교해보았을 때 가장 큰 차이점은 asynchronous 하다는 것이다. asynchronous한 BFT의 특징은 위에서도 잠시 언급했지만 프로토콜 상에서 timeout이 존재하지 않고 어떻게든 메세지가 도달하기만 하면 합의가 진행된다는 것이다. 이러한 특징은 네트워크가 안정적이든 불안정하든 네트워크가 제공하는 대역폭에 맞춰서 throughput을 낼 수 있다는 것이다.
Leaderless Consensus
또 PBFT와 비교했을 때 HoneyBadgerBFT가 가지는 특징 중 하나는 리더 노드가 존재하지 않는다는 것이다. HoneyBadgerBFT에서 합의에 참여하는 모든 노드들은 블럭에 들어갈 트랜잭션을 제시할 수 있는 Leader이며 HoneyBadgerBFT에서는 이 노드들을 Proposer라고 칭한다. 이러한 특징은 PBFT에서 리더 노드가 공격에 의해 멈춰서 영원히 프로토콜이 진행되지 않을 수도 있다는 문제점을 해결할 수 있다.
Efficient and Secure Message Distribution
HoneyBadgerBFT는 과거 다른 연구에서 소개되었던 다양한 기술들을 이용하여 효율적으로 메세지를 효율적이고 안전하게 전달할 수 있는 방법을 제시하였다. 예를 들어 각 노드가 자신이 가진 트랜잭션을 네트워크 구성원들에게 전파를 할 때 Reed-Solomon erasure coding 방식을 통해 트랜잭션 일부가 유실되어도 정상적으로 데이터를 전달할 수 있게 하였고 더불어 네트워크의 대역폭 사용량도 절약할 수 있다. 그리고 암호화 방식 중 하나인 Threshold encryption을 통해서 메세지를 암호화하고 악의적인 노드가 선별적으로 트랜잭션을 블럭에 담을 수 있는 문제를 차단하여 검열 저항성도 확보하였다.
HoneyBadgerBFT Mechanism
HoneyBadgerBFT가 어떤 식으로 동작하는지 좀 더 자세히 살펴보기에 앞서 HoneyBadgerBFT가 해결하려 하는 문제를 명확하게 살펴보자.
한 가지 짚고 넘어가야할 것은 HoneyBadgerBFT의 목표는 최종적으로 블록체인에 연결될 블록을 만드는 것이 아니라 네트워크 구성원 모두가 공통으로 동일한 순서를 가진 트랜잭션 집합을 가지도록 하는 것이다. 트랜잭션을 검증, 블록체인의 상태를 업데이트하고 스마트 컨트랙트를 실행하는 등 트랜잭션이 블록체인과 인터렉션하는 부분은 HoneyBadgerBFT의 책임이 아니라 HoneyBadgerBFT를 사용하는 다른 블록체인 레이어에서 해야하는 일이다.
최상위 레벨에서 봤을 때 HoneyBadgerBFT는 클라이언트로부터 트랜잭션을 받아서 보관하고 있고 비동기적으로 합의를 마칠 때마다 클라이언트가 전송한 트랜잭션들 중 일부가 담긴 트랜잭션 집합을 클라이언트에게 반환한다. 클라이언트가 보낸 트랜잭션을 제외했을 때 집합에 담긴 다른 트랜잭션들은 다른 클라이언트들이 다른 노드들에게 보낸 트랜잭션들이 담겨있다.
이러한 일을 처리하기 위해서 HoneyBadgerBFT의 시스템은 여러 컴포넌트들이 협력하고 있다.
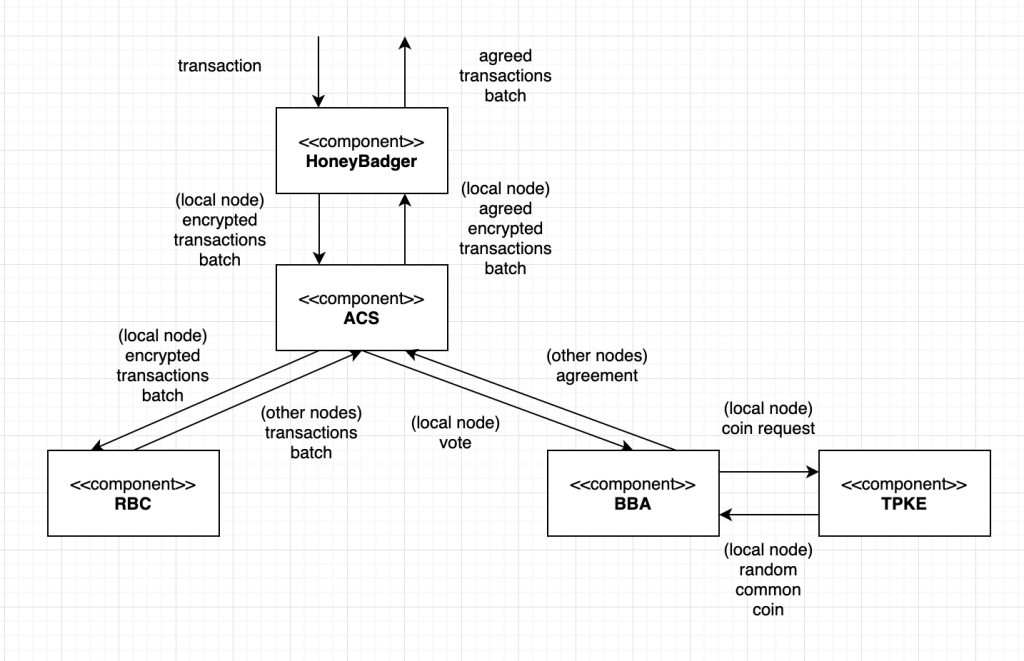
Threshold Encryption (TPKE)
Threshold encryption 암호화 방식은 HBBFT에서 사용하는 분산 암호화 알고리즘이다. 네트워크 구성원들은 하나의 마스터 공개키를 공유하고, 이를 이용하여 데이터를 암호화한다. 이 암호화 데이터를 복호화 하려면, 정해진 수 이상의 구성원이 힘을 합쳐야만 복호화 할 수 있다. 이 때 구성원들 중 몇 명이 모여야 복호화를 할 수 있는지를 정하는데, BFT에서는 이 값을 보통 f+1로 설정하여 비잔틴 노드들끼리만 있을 때 데이터를 복호화할 수 없게 만든다. TPKE는 다음과 같은 네 단계로 진행된다.
Setup
Setup 단계에서는 네트워크 구성원 모두에게 공개된 하나의 공개키와 각자만 알고 있는 개인키를 발급한다. 이 공개키와 개인키는 이산 대수(Discrete Logarithm)의 어려움을 기반으로 설계된 타원 곡선(Elliptic Curve)을 이용하여 만들어진다. 또한 데이터를 복호화할 때 몇 명의 구성원이 참여해야할지를 나타내는 임계값(threshold)를 정한다.
HoneyBadger BFT에서 Setup 단계는 최초로 네트워크를 구성할 때 이루어진다. 키를 발급해주는 대상은 CA와 같은 믿을 수 있는 제 3자가 될 수도 있으며, 다른 방법은 2003년 ‘Threshold signatures, multisignatures and blind signatures based on the gap-diffie-hellman-group signature scheme’ 에서 소개된 방식과 같은 distributed key generation 프로토콜을 사용하는 방법도 있다. 그런데 지금까지 알려진 distributed key generation 프로토콜은 모두 timing assumption에 의존하고 있어 최초로 네트워크를 구성할 때는 비동기성을 보장하지 않을 수 있다.
Encryption
네트워크 구성원 중 한 명이 데이터를 암호화할 때는 네트워크 내에 공유되고 있는 마스터 공개키를 이용한다. 타원 곡선에서 만들어진 공개키를 이용해 메세지를 암호화 한 후, 각 노드들에게 전송한다.
DecShare
각 노드가 자신이 받은 암호화 메세지를 복호화 하려면, Decryption Share 라고 하는 해독 조각들을 모아야 한다. 이를 위해 각 노드들은 받은 메세지와 자신의 비밀키를 이용하여 고유한 Decryption Share를 생성하고, 다시 주변 노드들로 전송한다. 이렇게 유효한 Decryption Share를 임계값(Threashold) 이상 수신한 노드만이 메세지를 복호화 할 수 있다.
Decryption
임계값 이상의 Decryption Share를 수신한 노드는 원문을 복호화할 수 있다. 이 때, 다항식의 보간을 이용하는 Shamir secret share 가 사용된다.
HoneyBadger
HoneyBadger 컴포넌트에서는 ACS에게 전달해줄 트랜잭션 배치를 만든다. CPU 자원 낭비를 막고 효율적으로 throughput을 높이기 위해서 클라이언트로부터 트랜잭션이 넘어올 때마다 바로 합의를 하기위해 네트워크에 전파하는 것이 아니라 HoneyBadger 컴포넌트 내부에서 버퍼를 두고 트랜잭션을 보관하고 이전 라운드의 합의를 마치고나면 다음 라운드의 합의를 진행하기 위해 버퍼에서 B/N 개의 트랜잭션을 꺼내서 배치를 만든다. 이 때 B는 매 라운드마다 합의할 배치 사이즈를 나타내고 N은 네트워크에 참여하고 있는 노드의 숫자를 말한다.
HoneyBadgerBFT는 라운드의 개념을 가지고 있다. Asynchronous BFT이기 때문에 여러 노드가 한 노드에게 메세지를 보냈을 때 어떤 노드의 메세지가 먼저 도달할지는 알 수 없다. HoneyBadgerBFT에서는 각 노드가 자신만의 독립적인 라운드가 존재하고 메세지를 전달할 때 자신의 라운드를 담아서 보내는데 그 결과 메세지를 받은 노드는 다른 노드가 어떤 라운드의 메세지를 보냈는지 확인할 수 있고 현재 자신의 라운드와 비교했을 때 그 크기에 따라서 다른 방식으로 핸들링하게 된다. 기본적으로 자신보다 낮은 라운드의 메세지를 받았을 때는 이미 이전 라운드에서 합의를 마친 상태기 때문에 무시하고, 자신보다 높은 라운드의 메세지를 받았을 때는 자신이 현재 라운드를 마치고 미래의 라운드의 합의를 진행할 때 필요한 메세지이기 때문에 라운드 별로 메세지를 보관하고 있다.
그렇기 때문에 어떤 한 시점에서 네트워크 내 노드들은 모두 같은 라운드를 가지는 않는다. 라운드는 각 노드가 가지고 있고 각 노드가 독립적으로 관리하는 값이기 때문이다.

위의 표는 논문에서 발췌했고 HoneyBadger 컴포넌트의 알고리즘을 나타낸 것이다. 앞에서 간단히 설명했듯이 HoneyBadger 컴포넌트는 내부적으로 버퍼를 가지고 있고 버퍼에 클라이언트로부터 받은 트랜잭션을 저장하고 있다. 그리고 새로운 라운드가 시작 되면 그 중 B/N 개의 트랜잭션을 랜덤으로 골라서 하나의 배치로 만든다.
그런데 트랜잭션을 큐에서 랜덤으로 고르는 이유가 있을까? 뒤에서 설명할 ACS 컴포넌트의 비용은 ACS가 다른 노드들에게 보낼 트랜잭션 배치 크기에 비례한다. 크기가 클수록 사용하는 대역폭이 클 것이다. 그렇다면 동일한 트랜잭션 배치를 노드들에게 전파할 때 다양한 클라이언트들의 트랜잭션을 한 라운드의 합의에서 처리하는 것이 전체 클라이언트들의 입장에서는 더 효율적일 것이다.
이 때 트랜잭션 배치를 만들 때 버퍼 앞쪽에서부터 트랜잭션을 가져오면 동일한 클라이언트의 트랜잭션을 가져올 확률이 높다. 그래서 최대한 서로 다른 클라이언트들의 트랜잭션을 골라 배치를 만들기 위해 랜덤으로 트랜잭션을 가져온다.
그리고 만든 배치를 threshold encryption을 통해서 암호화하고 암호화된 데이터를 HoneyBadgerBFT의 ACS에게 전달한다. 이 때 트랜잭션 배치를 그대로 ACS에 전달하는게 아니라 threshold encryption으로 암호화를 한 다음 전달하는데 이를 통해 다른 악의적인 노드의 ACS에서 특정 클라이언트의 트랜잭션만 다시 전파하는 등 노드가 선별적으로 트랜잭션을 골라내는 행위를 방지할 수 있다. 이와 같이 HoneyBadger 컴포넌트는 threshold encryption을 통해 검열 저항성을 확보한다.
ACS는 합의를 마치면 그 결과값을 다시 HoneyBadger 컴포넌트로 전달하는데 이를 다시 복호화하기 위해서는 f+1 명의 노드가 힘을 합쳐야 다시 데이터를 복호화할 수 있다. 복호화된 트랜잭션 배치들은 최종적으로 어플리케이션으로 전달된다.
Reliable Broadcast (RBC)
RBC의 목표는 현재 라운드에서 만들어진 트랜잭션 배치를 네트워크 내 합의에 참여하는 다른 노드들에게 전파하는 것이다. Broadcast가 Reliable 하다는 것은 ‘송신을 했으면 수신을 보장한다.’라는 뜻이다. 즉 RBC는 프로토콜 적으로 모든 노드가 트랜잭션 배치를 받는 것을 보장하는 Broadcast이다.
RBC에서는 네트워크의 합의에 참여하는 노드의 수(N)만큼 트랜잭션 배치를 쪼갠 후, 각각의 노드에게 트랜잭션 배치를 전파하게 된다. 여기서 사용되는 것이 Erasure coding이라는 스토리지 데이터 보존 및 복제기법이 사용된다. 이것은 일정 갯수 만큼의 데이터를 유실하여도 원본 데이터를 복구 할 수 있다는 특징개념을 가지고 있다. 핵심 개념만 정리하자면, RBC에서 사용되는 Erasure coding이라는 것은 데이터를 N개로 쪼개고 2f개 만큼의 parity 데이터를 만든다. 즉 RBC 과정 중(전파 중) 데이터를 2f개 만큼 유실하더라도 나머지의 데이터로 원본 데이터가 복구 가능하다는 것이다.
트랜잭션 배치를 Erasure coding을 이용해 쪼갠 후, 합의에 참여하는 노드들에게 전파하는 과정은 아래의 로직을 통해 메시지들을 전파하면서 프로토콜을 완성해 나간다.
RBC 프로토콜에서 사용되는 메시지는 VAL, ECHO, READY 세 가지가 있다. 이 메시지들을 다음과 같은 특징을 가지면서 네트워크에 전파된다.

알고리즘에 대해서 설명하기 전에 등장하는 용어들과 상황에 대해서 간단히 정리하면 네트워크에는 N개의 노드가 있고 각 노드는 P(i), i는 sender와 P(j), j는 receiver로 표현한다. 그리고 원본 데이터는 v이며 v를 Erasure coding을 통해 쪼갠 데이터들을 s(1…N)라고 칭한다. s(1…N)들을 이용해서 머클 트리를 만든다. 머클 트리 루트 해시를 h라고 칭한다. s(j)를 h를 만드는데 필요한 branch들을 b(j)라고 칭한다.
VAL 메세지를 보내는 단계에서 합의를 시작하는 노드 i가 네트워크의 모든 노드들에게 VAL(h, b(j), s(j))메세지를 브로드캐스트한다. VAL(h, b(i), s(i))를 받는 노드들은 자신과 i를 제외한 모든 노드들에게 ECHO(h, b(i), s(i))메시지를 멀티캐스트한다.
ECHO 메세지를 보내는 단계에서는 다른 노드(j)로 부터 ECHO(h, b(j), s(j)) 메시지를 받을 때, s(j), b(j)를 이용해 h가 유효한지 검사하고 유효하지 않으면 버린다. N-f 개 노드로부터 각각 다른 ECHO 메시지를 받으면 N-f 개의 s를 interpolate(논문의 decode와 같은 맥락) 한다. 그리고 자신이 가진 머클 트리 루트 해시와 interpolate된 머클 트리 루트 해시를 비교하여 다르면 합의를 무산시킨다. 마지막으로 READY(h) 메시지를 아직 보내지 않았으면 멀티캐스트한다.
READY 메세지를 보내는 단계에서는 READY(h) 메시지와 일치하는 f + 1 개의 메시지를 수신했을 때, READY(h)를 아직 전파하지 않았다면 READY(h)를 멀티캐스트한다. READY(h) 메시지와 일치하는 2f + 1 개의 메시지를 수신했을 때, N-2f 개의 ECHO 메시지를 기다린다. N-2f 개의 ECHO메시지가 도착하면 데이터를 erasure coding을 이용해 원본 형태(v)로 interpolate(논문의 decode와 같은 맥락)한다.
위의 ECHO와 READY 로직에서 interpolate와 decode를 나누어 놓았다. 하지만 N-2f의 데이터를 interpolate하여 머클 트리 루트 해시를 계산한다는 것은 사실상 erasure coding을 통해 원본데이터를 decode한다는 의미와 동일하다. 실제로 논문에서 구현한 코드에서도 둘의 의미를 동일하게 보고 구현하였다.
Binary Byzantine Agreement (BBA)
BBA는 합의 과정을 다루는 컴포넌트이다. BBA에서는 매 라운드 별로 어떤 노드의 배치가 집합에 포함될지를 결정한다. HoneyBadgerBFT에서 각 노드 별로 현재 합의에 참여하고 있는 네트워크 노드의 숫자만큼 Binary Agreement 인스턴스를 가지고 있다. 그리고 하나의 인스턴스는 하나의 노드에 대해서 해당 노드의 트랜잭션 배치를 포함시킬지 말지에 대해서 투표를 하고 결정한다.
Binary Byzantine Agreement는 이름에서 나타내듯이 노드들이 0 혹은 1에 대해서 합의를 하는 알고리즘을 말하는데 이 때 0과 1은 BBA가 어떤 어플리케이션에 사용되느냐에 따라서 의미가 달라진다. HoneyBadgerBFT에서 0은 네트워크 특정 한 노드의 트랜잭션 배치를 포함시키지 않겠다는 의미이고 1은 포함시키겠다는 의미이다.
예를 들어보자. 네트워크에는 4개의 노드가 존재하고 노드의 갯수가 4이기 때문에 한 노드는 4개의 BBA 인스턴스를 가지고 있다. i 번째 노드가 j 번째 노드에 대해 가지고 있는 BBA의 결과를 BBA(i, j)라 하자. 그렇다면 ‘BBA(1, 2)=1’ 의 의미는 1번 노드가 2번 노드의 트랜잭션 배치를 이번 라운드 합의에 포함시키겠다는 의미이다. 여기서 네트워크 내 모든 노드가 이번 라운드의 BBA 알고리즘을 마쳤을 때 BBA(i, 1) = 1 을 가진 i 노드의 갯수가 전체 네트워크 노드 숫자의 2/3을 넘으면 1번 노드의 배치를 이번 라운드 합의에 포함시킨다.
BBA이 어떻게 그 값을 합의할지에 대한 알고리즘은 다음과 같다.

위에 소개된 알고리즘은 하나의 노드 입장에서 전개되는 논리이다. 이해를 돕기 위해서 현재 네트워크 내에는 4개의 노드가 있고 1개의 비잔틴에 대해서 fault-tolerant 하다. BBA(1, 2)에 대해서 합의하는 상황을 상상해보자. 우선 1번 노드는 2번 노드의 트랜잭션 배치를 이번 라운드 합의에 포함시킬지 투표를 한다. 이 때 1번 노드는 2번 노드의 배치를 포함 시킨다는 투표를 했다고 가정하자.
다음으로 1번 노드는 자신이 2번 노드에 투표한 값을 네트워크 내 다른 노드들에게 전파한다. 이 때 자신이 투표한 값을 브로드캐스트하는 메세지를 BVAL 메세지라하고 위의 상황에서 1번 노드는 다른 노드들에게 BVAL(1)을 전파한 것이다.
그리고 다른 노드가 자신의 값을 브로드캐스트하기를 기다린다. 이 때 0 또는 1에 대해서 f+1 명의 노드가 브로드캐스트 했을 때 만약 그 값이 내가 이미 브로드캐스트한 값이라면 다시 전파하지 않고 그렇지 않다면 전파한다. 위의 상황에서는 내가 이미 BBA(1, 2)에 대해 BVAL(1)이라고 브로드캐스트를 한 상황이기 때문에 f+1명의 노드가 0이라고 전파를 했다면 1번 노드는 다시 BVAL(0)을 전파해야 하지만 반대의 상황이라면 전파하지 않는다. 그리고 0 또는 1 같은 값에 대해 2f+1 명의 노드가 전파했을 때 1번 노드는 bin_values라는 집합에 그 값을 저장한다. 여기서 bin_values에 저장된 값을 생각해보면 bin_values에 바이너리가 포함되려면 2f+1명의 노드가 같은 값을 브로드캐스트했다는 뜻이므로 네트워크 내 대다수의 노드가 투표한 값이라고 생각할 수 있다.
BBA가 시작될 때 비동기적으로 노드는 bin_values 집합에 값이 채워지기를 기다리고 있다. 이 때 BVAL 브로드캐스트 과정을 통해서 bin_values 집합에 값이 저장되면 AUX 메세지를 전파한다. 이 때 AUX 메세지는 간단히 말하면 다른 노드들이 전파한 값을 내가 다시 전파한다는 의미를 가지고 있다. 위의 상황에서 대다수의 노드들이 BBA(1, 2)의 값에 대해서 1이라고 투표를 한 상황이기 때문에 1번 노드는 AUX(1) 메세지를 다시 네트워크에 전파한다.
노드는 AUX 메세지를 브로드캐스트하고 나면 다른 노드들이 AUX 메세지를 전파하는 것을 듣고 있다. 이 때 0 또는 1 값에 대한 AUX 메세지를 N-f 개만큼 받으면 TPKE 컴포넌트로부터 common coin을 얻어서 만약 (common coin 값 mod 2) 한 결과가 N-f 개만큼 받은 AUX 메세지의 값과 동일하다면 해당 값을 BBA의 결과 값으로 결정한다. 만약 다르다면 전체 과정을 다시 한 번 반복한다.
Common Coin
Common Coin은 랜덤 속성을 가지는 바이너리이다. 0과 1이 나올 확률은 동일하고 이 랜덤 바이너리가 네트워크 내 노드들에게 공유되는 특징을 가지고 있다. 스포츠에서 경기를 시작하기 전 누가 선공을 할 것이냐를 결정할 때 심판이 던지는 동전을 상상하면 될 것 같다.
또한 Common Coin의 중요한 특징이 있는데 랜덤 바이너리가 임의의 노드로부터 생성되는 것을 방지하기 위해 특정 수의 노드가 코인 발행을 요청해야 비로소 Common Coin이 반환된다. 일반적으로 비잔틴 노드들로부터 Common Coin이 발행되는 것을 막기위해서 f+1명으로 코인 발행 요청 수를 설정한다.
그렇다면 BBA에 Common Coin이 왜 필요할까? 올바로 동작하는 노드와 비잔틴 노드를 포함해서 같은 값으로 ⅔ 이상 투표하는 경우는 그 값으로 결정하면 되기때문에 문제가 없다. 그런데 어떤 이유로 올바른 노드와 비잔틴 노드가 같은 값으로 ⅓~⅔ 사이의 비율로 투표했을 때 올바른 노드는 두 개의 값 중 하나를 선택해야 한다. 그런데 asynchronous한 상황에서 올바른 노드들도 다른 값으로 투표하는 상황이 있을 수 있으므로 이 둘 중 하나는 비잔틴이 담합을 한 값일 수도 있다. 그렇기 때문에 섣불리 이 둘 중 하나의 값을 결정할 수 없기 때문에 Common Coin을 이용한다. Common Coin은 위에서 설명한 특성상 올바른 노드들이 결정한 값이다. 그렇기 때문에 이는 신뢰할 수 있는 값이고 이를 이용해 BBA 알고리즘을 진행한다.
Common Coin을 생성하는 알고리즘은 Cachin의 ‘Random Oracles in Constantinople: Practical Asynchronous Byzantine Agreement using Cryptography’에 자세히 설명되어있다.
Asynchronous Common Subset (ACS)
ACS 컴포넌트는 HoneyBadgerBFT에서 가장 핵심적인 컴포넌트이다. ACS가 하는 일은 자신이 받은 트랜잭션 배치를 네트워크 내 다른 노드들에게 전파하고 자신도 다른 노드들로부터 트랜잭션을 받아서 이 중에 어떤 노드의 트랜잭션 배치를 이번 라운드 합의에 포함할지 말지에 대해서 결정한다.
기존에 ACS는 Cachin의 ‘Secure intrusion-tolerant replication on the internet. In Dependable Systems and Networks, 2002’를 비롯한 몇몇 연구들에서 소개되었다. ACS의 효용성에 대해서는 좋은 평가를 받았지만 HoneyBadgerBFT가 등장하기 이전에 Cachin과 Portiz가 구현한 ACS의 성능을 살펴보면 0.4tx/sec 밖에 되지 않아서 실질적으로 사용하기에는 어려워 보였다.
그런데 HoneyBadgerBFT에서는 RBC와 BBA를 통해 ACS 알고리즘을 구현함으로써 throughput을 대폭 증가시켰다. 논문에서는 각 노드에 대해서 ACS의 asymptotic cost를 O(N²) 에서 O(1)로 줄였다고 소개되고 있다.

위의 표는 ACS 컴포넌트 알고리즘 나타낸 것이다. 매 라운드마다 ACS는 네트워크 내 합의에 참여하는 노드 수 만큼 RBC, BBA 인스턴스를 가진다. 상위 레벨에서 RBC, BBA가 어떻게 ACS와 협력하는지에 대해서 설명하려고 한다.
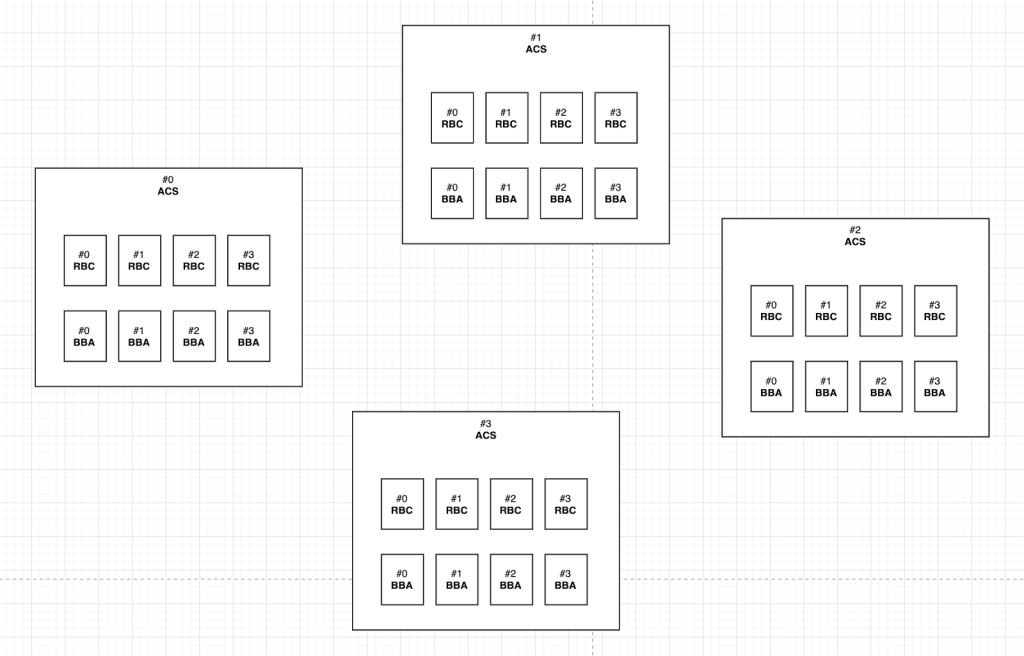
이해를 돕기 위해 하나의 상황을 가정해보자. 그림 2에서 현재 네트워크에는 4개의 노드가 존재하고 1개의 노드에 대해 fault-tolerant하다. 그리고 각 노드별로 ACS_(i)를 가지고 있고 i 번째 노드는 4개의 RBC_(i, j) (0<= j <=3)와 4개의 BBA_(i, j) (0 <= j <= 3)를 가지고 있다.
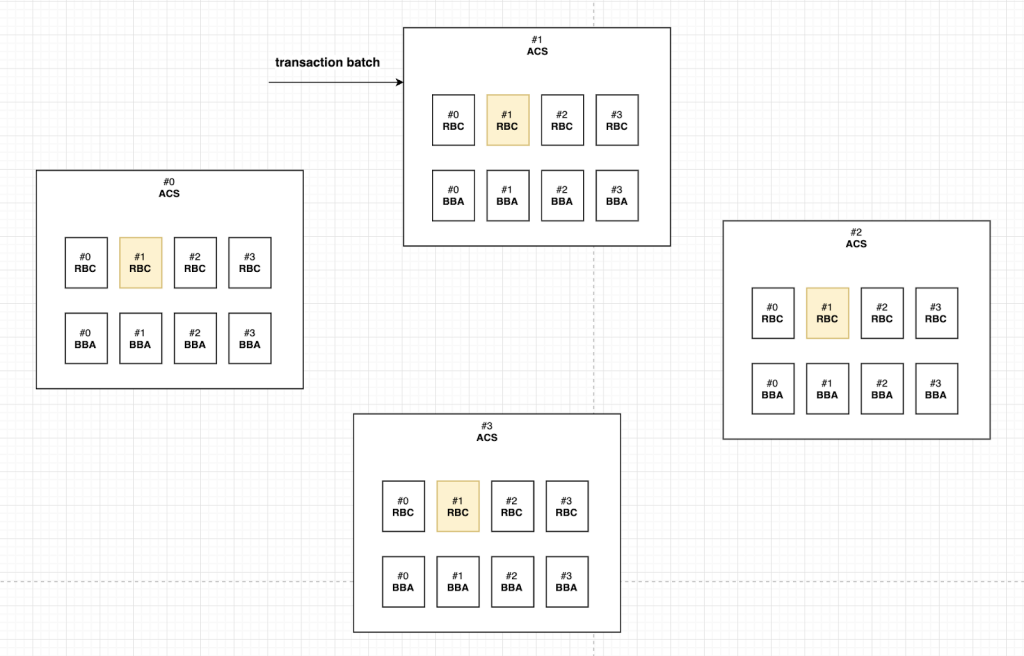
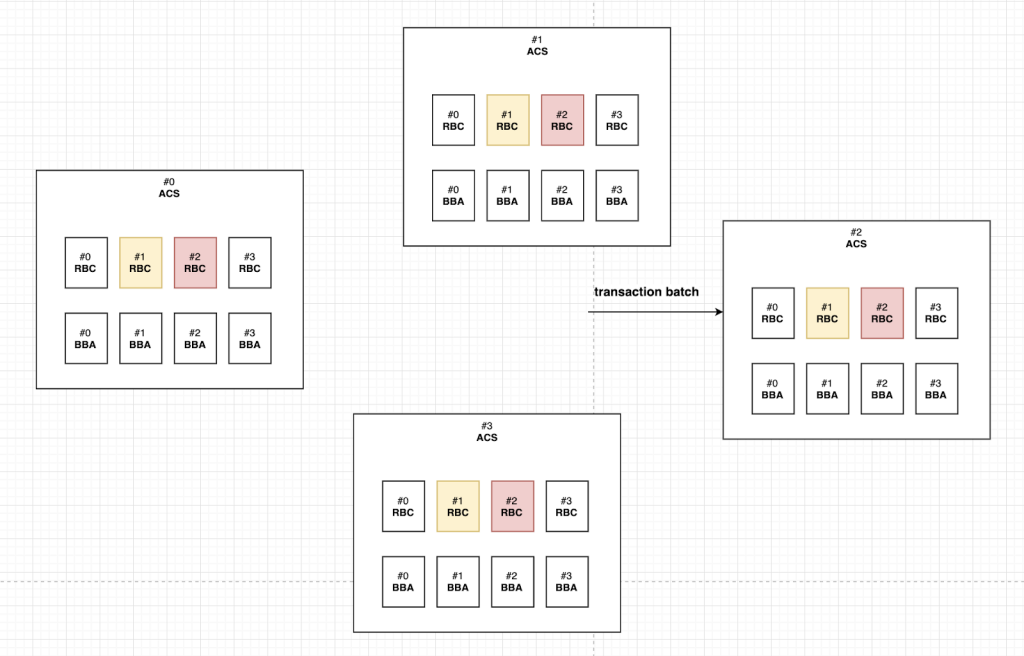
그림 3에서 1번 노드가 HoneyBadger 컴포넌트로부터 트랜잭션 배치를 받으면 RBC_(1, 1)에 입력값으로 넣어주고 reliable broadcast를 시작한다. 왜냐하면 자기 자신에 대한 RBC를 동작시켜야하기 때문이다. 이 때 HoneyBadgerBFT는 모두 비동기적으로 동작하기 때문에 동시에 다른 노드로부터 트랜잭션의 배치를 받아 RBC_(1, j)를 시작시킬 수 있다. 예를 들어 그림 4에서 2번 노드로부터 트랜잭션 배치가 동시에 도착했다고 가정하면 RBC_(1, 2) 를 시작시킨다.
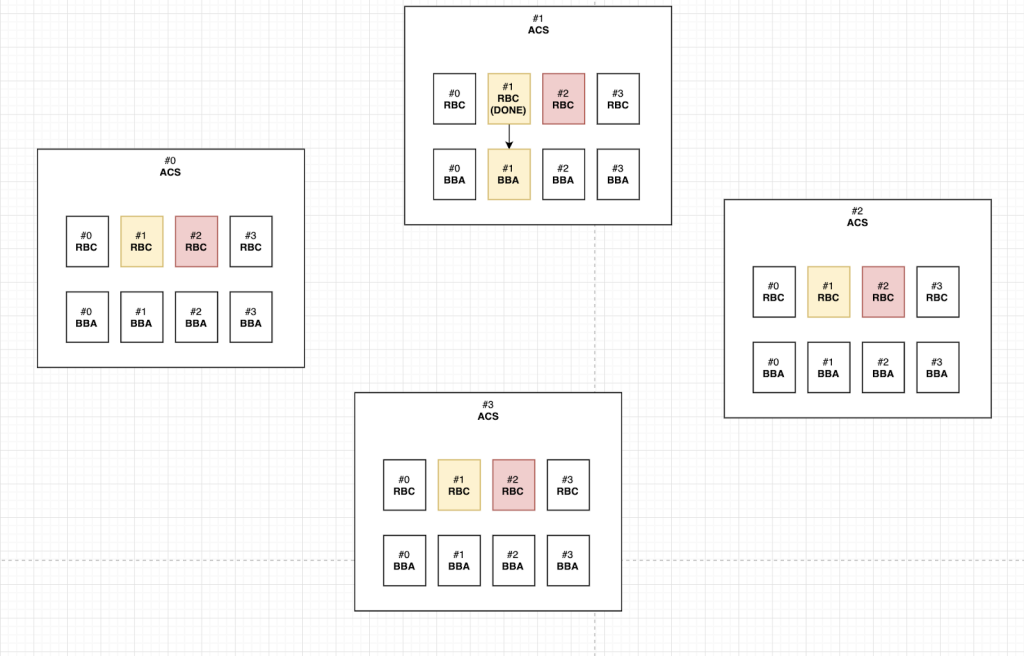
그리고 그림 5와같이 어떤 노드의 RBC가 먼저 끝날 수 있다. 해당 노드의 트랜잭션 배치를 다른 노드들에게 전파하는 과정을 마무리한 것이다. 그렇다면 해당 노드의 BBA에 1을 입력값으로 주고 해당 노드의 합의를 시작한다. BBA 1을 입력값으로 준다는 것은 ‘나는 해당 노드의 트랜잭션 배치를 받았다’라는 의미이다. 위의 상황을 예로 들어보면 1번 노드의 RBC_(1, 1) 과정이 끝났다면 BBA_(1, 1) 입력값으로 1을 준다는 것이다.
그런데 만약 한 노드의 ACS에서 N-f 개의 BBA 인스턴스가 1을 입력값으로 가지고 합의를 시작했다면 나머지 f개의 BBA 인스턴스는 RBC가 끝날 때까지 기다리지 않고 0을 입력값으로 주고 합의를 시작한다.
이렇게 보면 ACS 알고리즘이 단순해 보일 수 있지만 노드 간에 RBC, BBA 인스턴스 별로 각각 비동기적으로 메세지가 전달되기 때문에 다양한 시나리오가 생길 수 있다. 그래서 ACS에서 발생할 수 있는 몇 가지 상황들에 대해서 설명하려고 한다.
- 다른 N — f 개의 노드의 RBC가 끝나기 전에 RBC가 끝난 경우
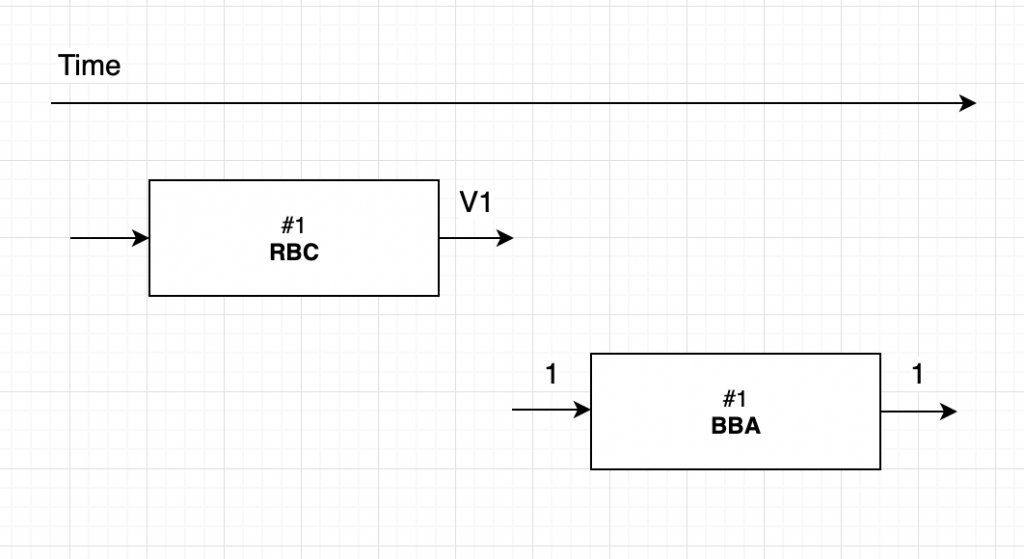
1번 노드 입장에서 1번 노드의 RBC가 끝났다고 생각해보자. 한 노드의 RBC가 끝났다는 것은 자신을 포함한 N-f의 노드들의 RBC 알고리즘도 끝났다는 뜻이다. 이 경우는 ACS가 해당 노드의 BBA에게 1을 입력값을 주고 합의를 시작한다.
2. 다른 N — f 개의 노드의 RBC가 끝나서 BBA가 합의를 0으로 시작한 경우
마찬가지로 1번 노드 입장에서 생각해보자. 위에서 설명했듯이 다른 N-f개의 노드의 RBC가 종료되면 아직 종료하지 못한 BBA는 0을 입력값으로 합의를 시작한다. 이 때 주목해야할 것은 아직 1번 노드의 RBC는 진행되고 있다는 것이다. 아직 1번 노드의 네트워크 환경이 불안정해서 데이터 전송이 더뎌질 수 있다.
여기서 다시 두 가지 상황이 발생할 수 있다.
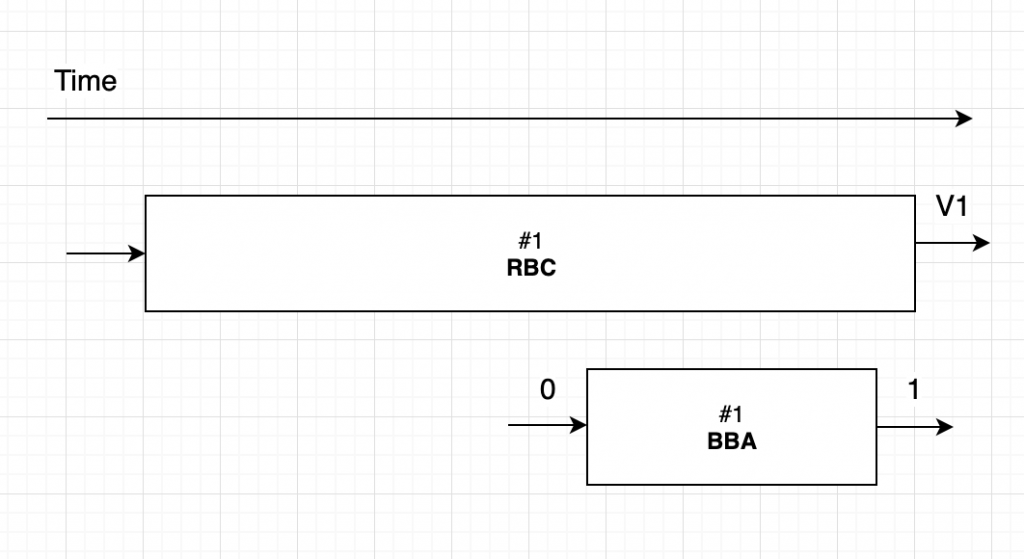
첫 번째는 1번 BBA가 0의 값으로 합의를 진행했지만 합의 결과 1이 나온 경우이다. 이 때는 자신을 포함한 N-f개의 노드가 1번 BBA에 대해서 1을 입력 값으로 합의를 시작했다는 뜻이다. 다시 말해 N-f개의 노드가 1번 RBC를 성공적으로 끝마쳤다. 그렇기 때문에 1번 노드는 자신의 RBC가 끝나는 것을 기다려야한다.
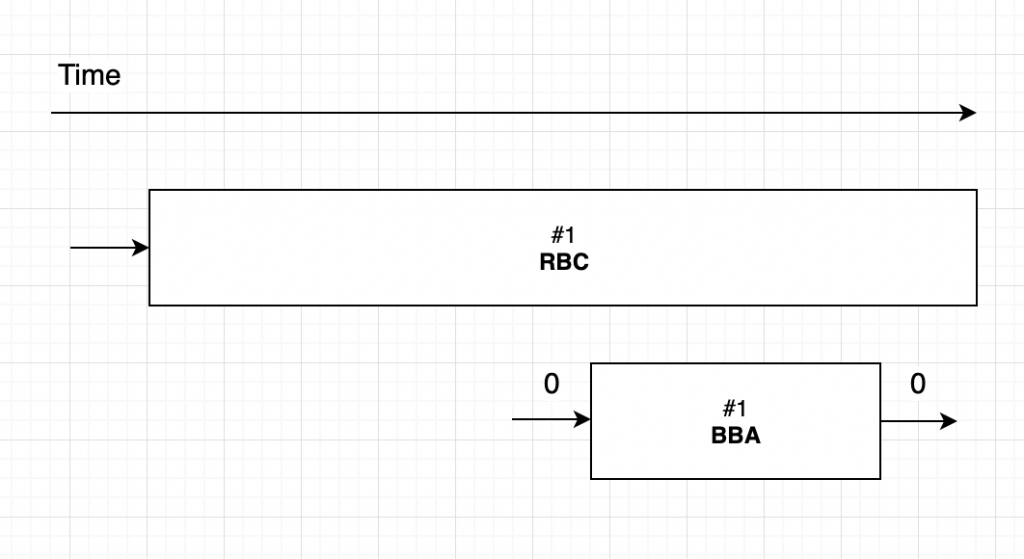
두 번째는 1번 BBA가 0의 값으로 합의를 진행했지만 합의 결과 0이 나온 경우이다. 이 경우는 어떤 이유에서든 1번 BBA를 RBC가 끝나고 나서 시작한 노드가 N-f개가 되지 않는다는 이야기고 다시 말해 RBC를 끝마친 노드가 N-f개가 되지 않는다는 뜻이다. 따라서 1번 노드는 1번 RBC가 끝나는 것을 기다리지 않아도 된다.
이와 같은 과정을 통해 ACS의 모든 BBA 인스턴스들이 합의를 마쳤다면 네트워크 내의 모든 노드들에게 자신의 트랜잭션 배치를 전파했고 나 자신도 마찬가지로 다른 노드들로부터 트랜잭션 배치를 받았으며 모두가 이번 라운드에서 어떤 노드의 배치를 포함시키고 어떤 것은 제외시킬 것인지 합의를 마쳤다는 뜻이므로 ACS의 알고리즘을 종료하고 모든 노드의 트랜잭션 배치를 합친 것을 다시 HoneyBadger 컴포넌트로 올려보낸다.
정리
이번 글에서는 HoneyBadgerBFT가 무엇이며 어떤 방식으로 동작하는지에 대해서 살펴보았다. 현재 대부분 사용되고 있는 BFT가 partial synchronous한 시스템이지만 HoneyBadgerBFT는 실용적으로 사용될 수 있도록 throughput을 고려한 asynchronous 한 BFT 프로토콜을 제시했다는 점에서 의미가 있다.
asynchronous한 방식은 time assumption에 의존하지 않기 때문에 partial synchronous한 방식보다 네트워크 환경에 영향을 덜 받고 최적의 throughput을 만들어낼 수 있다. 또한 한 명의 리더가 존재하지 않고 네트워크 구성원들이 모두 트랜잭션 제안자가 됨으로써 PBFT와같은 BFT에서 리더가 공격을 받았을 때 합의가 멈춘다는 문제점을 해결할 수 있었고 Erasuring coding을 통해 트랜잭션 배치를 나누어 전파함으로써 트랜잭션 제안자가 필요한 대역폭의 부담을 줄일 수 있었다.
또한 threshold encryption을 통해 검열 저항성을 확보할 수 있었는데 이것은 구성원 다수가 모여야 복호화를 할 수 있다는 threshold encryption의 특징때문이다. 덕분에 악의적인 노드가 선별적으로 특정 클라이언트의 트랜잭션을 제출하는 행위를 막을 수 있었다.
마지막으로 RBC와 BBA를 통해 ACS 알고리즘을 구현함으로써 asymptotic cost를 크게 줄일 수 있었고 비로소 최초로 실용성을 가진 asynchronous BFT가 될 수 있었다.
구현한 HoneyBadgerBFT 구현체는 여기에서 확인하실 수 있습니다.