Kubernetes Controller 구현해보기
이전에 다른 포스팅에서 Kubernetes CRD와 Controller에 대해서 개념적인 글을 작성하였다. 이번 포스팅은 시간이 꽤 지났지만 코드 레벨에서 어떤 식으로 CRD와 Controller를 만들 수 있는지에 대해서 작성해보려고 한다.
Requirements & Decisions
앞으로 다룰 이야기가 수월하게 흘러가고 현실감있게 받아들여질 수 있도록 가상의 요구사항을 하나 만들어보자.
- 시스템 장애 상황에 대비해서 주기적으로 유저 활동 로그를 찍어서 파일로 저장하는 Logger를 만들 것이다.
- Kubernetes 클러스터를 호스팅하고 있는 클라우드 서비스가 죽지않는 이상 적어도 하나 이상의 Logger는 살아남아서 계속 유저들의 활동 로그들을 찍어서 저장해야한다.
이 정도 요구사항이라면 로깅 어플리케이션을 하나 만든 다음, 도커 이미지를 만들어 Deployment로 해당 서비스를 배포해도 괜찮을 것이다.
하지만 가까운 미래에 '유저 등급별 로그 파일 저장 주기 설정'과 같은 도메인 로직이 유저 활동 Logger에 추가될 가능성이 있다. 하지만 이러한 사항들을 제대로 반영할 수 있는 resource가 존재하지 않기 때문에 우리는 좀 더 공수를 들여서 유저 활동 Logger를 custom resource로 만들고 이를 관리할 수 있는 custom controller를 만들기로 결정하였다.
How custom controller manage custom resource.
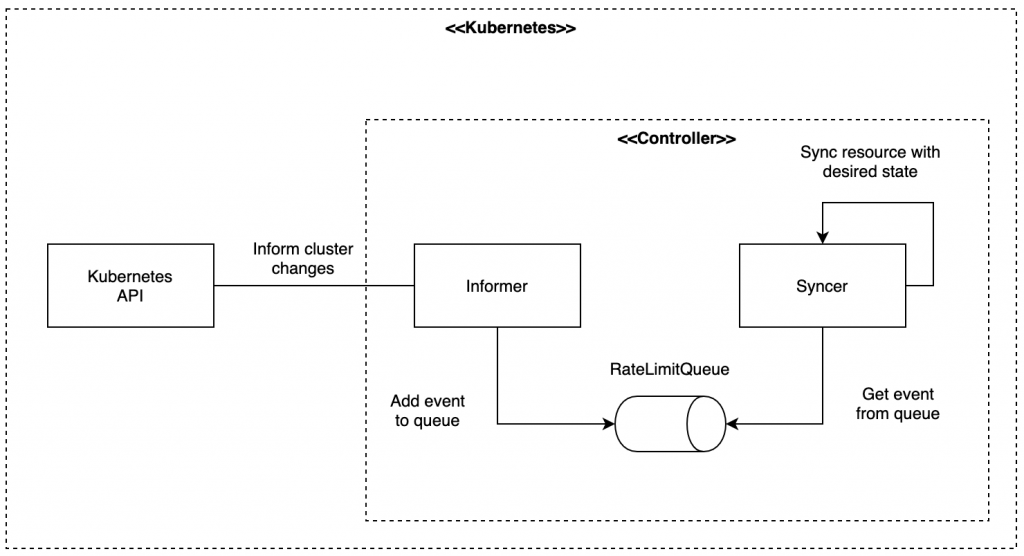
custom resource와 custom controller를 만들기 전에 custom controller가 어떻게 custom resource를 관리하는지 좀 더 디테일하게 알아보자.
이 둘간의 관계에 대해서 설명하려면 한 가지 개념을 더 알아야하는데 그것이 바로 informer이다.
informer는 Kubernetes 클러스터와 Controller 사이에서 중개자 역할을 한다. informer는 특정 resource 타입에 대해 클러스터에서 변화가 생길 때마다 해당 이벤트를 들을 수 있는 이벤트 핸들러를 등록할 수 있다.
이벤트 핸들러를 통해 넘어온 이벤트들은 보통 큐에 저장하고 Controller는 큐의 반대편에서 informer가 넘긴 이벤트를 구독하여 이벤트가 넘어올 때마다 이벤트의 타입에 따라서 적절하게 핸들링한다.
이벤트의 형태는 리소스에 대한 액션 (create, update, delete)과 리소스 키(일반적으로 리소스의 namespace/name)의 조합으로 구성되어있다.
Generate CRD Informer, Client
기본적으로 Deployment, Daemon, Service와 같은 Kubernetes core resource와 인터렉션할 수 있는 client나 core resource의 변화를 들을 수 있는 informer는 Kubernetes 라이브러리에서 제공된다.
하지만 우리가 이제 생성할 CRD와 인터렉션할 수 있는 client나 informer는 아직 이 세상에 존재하지 않는다. 그렇기 때문에 custom controller를 생성하기 위해서는 우선 우리가 만들 CRD에 대한 변화를 포착할 수 있는 informer와 client를 생성해야한다.
다행히도 Kubernetes에서는 CRD에 대한 기본적인 자료구조를 생성했을 때 해당 CRD에 대해서 informer와 client를 생성해주는 CRD informer, client auto-gen 라이브러리가 존재한다.
만약 이런 것이 존재하지 않았다면 우리는 Kubernetes에서 제공해주는 informer, client 인터페이스를 보고 그에 대한 low-level 구현체를 우리가 직접 작성해줬어야했을 것이다.
그래서 우선 controller에 대한 로직을 작성하기 전에 CRD에 대한 자료 구조를 정하고 auto-gen을 위한 사전작업을 먼저 진행할 것이다.
Add boilerplate code for generator
우선 우리가 만들 custom resource를 정의할 디렉토리를 생성하자. 다음과 같은 경로에pkg/apis/logger/v1 디렉토리를 생성해준다.
package logger
const (
GroupName = "example.com"
)그리고 유저 활동 로거의 그룹 이름을 설정해주어야하는데 이는 pkg/apis/logger/register.go 에 파일을 생성하여 아래와 같이 우리가 생성할 리소스에 대한 그룹명을 정해준다.
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
// +genclient
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
type Logger struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata"`
Status LoggerStatus `json:"status,omitempty"`
Spec LoggerSpec `json:"spec,omitempty"`
}
type LoggerStatus struct {
Value StatusValue `json:"state"`
}
type StatusValue string
const (
Available StatusValue = "Available"
Unavailable StatusValue = "Unavailable"
)
type LoggerSpec struct {
Name string `json:"name"`
TimeInterval int `json:"timeInterval"`
Replicas *int32 `json:"replicas"`
}
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
type LoggerList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `son:"metadata,omitempty"`
Items []*Logger `json:"loggers"`
}먼저 요구사항을 만족시킬 수 있는 Logger Resource를 생성하기 위해 필요한 자료구조를 만든다. Logger struct와 같이 struct 최상위에서는 Kubernetes resource로서 역할을 하기 위한 기본적인 메타데이터 필드를 넣고 우리가 커스텀하게 만들 구체적인 필드는 Spec 아래에 정의한다.
첫 번째 버전에서는 우선 활동 기록 로거의 이름 Name과 몇 초 주기로 활동기록을 가져올지를 나타내는 TimeInterval에 대해서 정의한다.
그리고 // +<tag_name>[=value] 형태의 주석들을 살펴볼 수 있는데 이것들은 code generator을 위한 주석이다. code generator는 해당 주석들을 만났을 때 어떻게 동작할지에 대해서 알고 있다.
+genclient: 현재 패키지에 정의된 자료 구조에 대해서 Kubernetes Client를 생성하라. 사용자는 해당 client를 통해 Kubernetes와 인터렉션할 수 있다.+k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object: 다음 코드에 대해서 deep copy 로직을 생성하라.
// +k8s:deepcopy-gen=package
// +groupName=example.com
package v1
pkg/apis/logger/v1/doc.go 해당 파일에 위와 같은 주석을 추가해준다. 이 파일에 명시된 주석들은 해당 패키지에 존재하는 모든 코드들에 대해 영향을 준다.
예를 들어 v1 패키지에 속한 모든 타입들에 대해 deep copy 함수가 생성될 것이고 Kuberetes API group명은 example.com이 될 것이다.
package v1
import (
"github.com/zeroFruit/operator-demo/pkg/worker/apis/logger"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/apimachinery/pkg/runtime/schema"
)
var SchemeGroupVersion = schema.GroupVersion{
Group: logger.GroupName,
Version: "v1",
}
var (
SchemeBuilder = runtime.NewSchemeBuilder(addKnownTypes)
AddToScheme = SchemeBuilder.AddToScheme
)
func Resource(resource string) schema.GroupResource {
return SchemeGroupVersion.WithResource(resource).GroupResource()
}
func addKnownTypes(scheme *runtime.Scheme) error {
scheme.AddKnownTypes(
SchemeGroupVersion,
&Logger{},
&LoggerList{},
)
metav1.AddToGroupVersion(scheme, SchemeGroupVersion)
return nil
}
마지막으로 CRD client가 우리가 새롭게 정의한 타입에 대해서 알기 위해서는 위의 코드에서와 같이 AddToScheme 과 Resource에 대해서 정의해줘야한다. 이를 이용하여 code generator가 CRD client 코드를 생성하게 된다.
여기까지해서 code generator가 코드를 생성하는데 필요한 boilerplate 코드들을 모두 작성하였다. 이제 CRD에 대한 Kubernetes client와 informer를 생성해보자.
Run code generator
code generator는 https://github.com/kubernetes/code-generator 여기에서 살펴볼 수 있다.
code generator를 사용하기 위해서 우선 $GOPATH/k8s.io에 해당 레포지토리를 클론하자.
사용 방법은 다음과 같다.
cd $GOPATH/src/github.com/zeroFruit/operator-demo
$GOPATH/src/k8s.io/code-generator/generate-groups.sh all \
github.com/zeroFruit/operator-demo/pkg/client \
github.com/zeroFruit/operator-demo/pkg/apis \
"logger:v1"$GOPATH/src/k8s.io/code-generator/generate-groups.sh all:generate-groups.sh를 실행시키고allsubcommand를 통해 lister, informer, client를 모두 생성한다.github.com/zeroFruit/operator-demo/pkg/client: 현재 데모 코드를github.com/zeroFruit/operator-demo에서 작성하고 있고 client를 생성할 디렉토리 위치를 가리킨다. 이 때$GOPATH/src에서 relative한 경로를 써준다.github.com/zeroFruit/operator-demo/pkg/apis: CRD 자료구조를 작성한 디렉토리를 가리킨다. deep copy 함수가 생성된다. 이 때$GOPATH/src에서 relative한 경로를 써준다."logger:v1":<resource_name>:<version>형태로 입력해준다.
UserActivityLoggerService
다음으로 우리가 Kubernetes 클러스터에 올릴 실제 유저 활동 로깅 서비스를 구현해보자. 이 부분은 Controller와 직접적인 관련이 없으니 최대한 간단하게 만들고 넘어가자.
if (process.argv.length < 4) {
throw new Error('logger name and timeInterval must be given.');
}
const name = process.argv[2];
const timeInterval = parseInt(process.argv[3]);
console.log('Logger Name: ', name);
console.log('Logger TimeInterval: ', timeInterval);
const logger = setInterval(function() {
console.log('Logging user activity ...', new Date());
}, timeInterval);
process.on('exit', code => {
console.log('process exit');
clearInterval(logger);
});
로깅 서비스는 외부로부터 name과 timeInterval을 주입받고 이를 토대로 유저 활동 로그를 찍어나간다. 이전에 정의한 Logger Resource에서 Replicas와 같은 정보는 보이지 않는데 이러한 속성은 로깅 서비스가 몰라도 되는 부분이다.
FROM node:10-alpine3.10
# Create app directory
WORKDIR /usr/src/app
# Bundle app source
COPY . .
ENTRYPOINT [ "node", "main.js" ]마지막으로 Dockerfile을 생성하고 마무리한다.
Implement Controller
이제 위에서 만든 UserActivityLoggerService를 Kubernetes 클러스터에서 관리해줄 Controller를 만들 차례이다.
type Controller struct {
kubeclient kubernetes.Interface
loggerclient loggerclientset.Interface
deploymentsLister appslisters.DeploymentLister
deploymentsSynced cache.InformerSynced
loggerLister loggerlisterv1.LoggerLister
loggerSynced cache.InformerSynced
queue workqueue.RateLimitingInterface
recorder record.EventRecorder
}kubeclient:kubeclient는 Kubernetes의 Core resource를 관리하기위해 필요하다. 조금 더 구체적으로는 우리가 처음에 정의한 Logger 커스텀 리소스가 필요로 하는 Deployment를 관리하기 위해 필요하다. Kubernetes API와 통신한다.loggerclient:loggerclient는 Logger 커스텀 리소스 자체를 관리하기 위해서 필요하다. Code generator로 만든 Logger custom clientset과 통신한다.deploymentLister:deploymentLister는 클러스터 내에 있는 Deployment resource들을 조회하는 책임을 가진다.deploymentSynced:deploymentSynced는 현재 클러스터 내부에 떠있는 Deployment resource와 etcd에 기록되어있는 desired state가 같은지 조회할 수 있는 함수이다.loggerSynced:loggerSynced는deploymentSynced와 마찬가지로 Logger 리소스가 desired state와 같은지 조회할 수 있는 함수이다.queue: 타입을 보면 추측할 수 있겠지만 rate limiting 기능이 들어있는 queue이다.recorder:recorder는 우리가 정의한 custom resource에서 발생하는 이벤트들을 기록하는 역할을 하는데 좀 더 자세한 설명은 생성자 부분에서 이어나가겠다.
New Controller
생성자 부분에서 살펴볼 부분들이 꽤 있는데 하나씩 설명하려고 한다.
func New(
kubeclient kubernetes.Interface,
loggerclient loggerclientset.Interface,
deploymentInformer appsinformers.DeploymentInformer,
loggerInformer loggerinformersv1.LoggerInformer) *Controller {
// create event broadcaster
// add Worker types to the default Kubernetes Scheme so events
// can be logged for Worker types
utilruntime.Must(loggerschemev1.AddToScheme(scheme.Scheme))
klog.V(4).Info("Creating event broadcaster")
eb := record.NewBroadcaster()
eb.StartLogging(klog.Infof)
eb.StartRecordingToSink(&typedcorev1.EventSinkImpl{
Interface: kubeclient.CoreV1().Events("default"),
})
recorder := eb.NewRecorder(scheme.Scheme, corev1.EventSource{
Component: controllerAgentName,
})
...
}주목해야할 부분은 eb.StartRecordingToSink 함수인데 EventSinkImpl의 Interface인자로 kubeclient를 넣고 있는 것을 확인할 수 있다.
// EventBroadcaster knows how to receive events and send them to any EventSink, watcher, or log.
type EventBroadcaster interface {
// StartRecordingToSink starts sending events received from this EventBroadcaster to the given
// sink. The return value can be ignored or used to stop recording, if desired.
StartRecordingToSink(sink EventSink) watch.Interface
}그리고 'StartRecordingToSink starts sending events received from this EventBroadcaster to the given sink.'를 통해서 우리는 이벤트들을 Kubernetes의 어딘가에 기록할 것이라는 추측할 수 있다.
내부를 살펴보면 알 수 있겠지만 실제로도 Kubernetes client가 클러스터 API를 이용하여 내부에 이벤트를 전송하고 잇다.
그렇다면 누가 이벤트를 생성하는 actor 역할을 하는지 궁금해할 수 있는데 그것은 eb.NewRecorder를 통해서 생성되는 recorder가 그 역할을 한다.
Event record가 정확히 어떻게 동작하는지 살펴보기 위해서 관련 코드를 다 뜯어봤는데 코드 디자인과 관련해서 배울 점이 많았다.
노션에 대충 정리는 해놨는데 글이 너무 길어질 것 같아 시간이 되면 관련 내용에 대해서 실제로 Kubernetes client는 Event record에 대해서 어떤 식으로 설계했고 왜 이런 식으로 코드를 짰는지 고민하는 글에 대해서 써보겠다.
func New(
kubeclient kubernetes.Interface,
loggerclient loggerclientset.Interface,
deploymentInformer appsinformers.DeploymentInformer,
loggerInformer loggerinformersv1.LoggerInformer) *Controller {
...
c := &Controller{
kubeclient: kubeclient,
loggerclient: loggerclient,
deploymentsLister: deploymentInformer.Lister(),
deploymentsSynced: deploymentInformer.Informer().HasSynced,
loggerLister: loggerInformer.Lister(),
loggerSynced: loggerInformer.Informer().HasSynced,
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "Workers"),
recorder: recorder,
}
loggerInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: c.enqueueWorker,
UpdateFunc: func(old, new interface{}) {
c.enqueueWorker(new)
},
//DeleteFunc: c.enqueueWorker,
})
deploymentInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: c.handleObject,
UpdateFunc: func(old, new interface{}) {
newDeployment := new.(*appsv1.Deployment)
oldDeployment := old.(*appsv1.Deployment)
if newDeployment.ResourceVersion == oldDeployment.ResourceVersion {
return
}
c.handleObject(new)
},
DeleteFunc: c.handleObject,
})
return c
}다음으로 c := &Controller{...}를 통해 Controller 인스턴스를 생성하고 있다.
마지막으로 loggerInformer와 deploymentInformer가 각자 watch하고 있는 resource에 변화가 생길 때마다 이를 핸들링할 수 있도록 변화에 대한 타입마다 이벤트 핸들러를 등록할 수 있다.
loggerInformer의 경우 새로운 Logger resource가 생성되거나 업데이트 될 때 enqueueWorker 함수를 호출하고 있다. deploymentInformer의 경우 Deployment resource가 생성되거나 삭제될 때 handleObject 함수를 호출한다.
enqueueWorker와 handleObject 모두 controller 내부적으로 관리되는 큐에 변화가 생긴 리소스에 대한 이벤트를 넣는 작업을 하는데 controller를 주기적으로 큐에서 이벤트를 꺼내서 싱크를 맞추는 작업을 수행한다. 이는 아래에서 더 자세히 설명하겠다.
이처럼 주기적으로 현재 Kubernetes 클러스터의 변화를 관찰하면서 변화가 생길 때마다 도메인 로직에 따라 실제 클러스터와 싱크를 맞추고 클러스터의 상태 정보를 업데이트하는 것이 핵심이다.
Run Controller
func (c *Controller) Run(workers int, stopCh <-chan struct{}) error {
defer utilruntime.HandleCrash()
defer c.queue.ShutDown()
...
klog.Info("Starting workers")
for i := 0; i < workers; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
klog.Info("Started workers")
<-stopCh
klog.Info("Shutting down workers")
return nil
}
func (c *Controller) runWorker() {
for c.processNext() {
}
}
New()를 통해 생성된 Controller가 Run()을 실행하면 무한 루프를 돌면서 processNext()를 통해 큐에 새로운 이벤트가 있는지 살펴본다.
Process Item from Queue
func (c *Controller) processNext() bool {
item, quit := c.queue.Get()
if quit {
return false
}
err := func(item interface{}) error {
defer c.queue.Done(item)
var key string
var ok bool
if key, ok = item.(string); !ok {
c.queue.Forget(item)
utilruntime.HandleError(fmt.Errorf("expected string in workqueue but got %#v", item))
return nil
}
if err := c.syncHandler(key); err != nil {
// Put the item back on the queue to handle any transient errors.
c.queue.AddRateLimited(key)
return fmt.Errorf("error syncing '%s': %s, requeuing", key, err.Error())
}
c.queue.Forget(item)
klog.Infof("Successfully synced '%s'", key)
return nil
}(item)
if err != nil {
utilruntime.HandleError(err)
return true
}
return true
}우선 큐가 종료되었는지 확인하고 종료되었다면 무한 루프를 종료하고 더 이상 큐에 새로운 이벤트가 있는지 확인하지 않는다.
중요한 것은 큐에 이벤트가 존재하는 경우인데 우선 큐의 존재하는 아이템이 이벤트가 맞는지부터 확인한다.
여기에서 큐에 들어가는 이벤트가 어떻게 만들어지는지 확인할 수 있다.
만약에 맞다면 syncHandler()를 호출하여 우리의 도메인 로직에 따라서 현재 state와 desired state를 비교하여 custom resource의 싱크를 맞춘다.
만약에 싱크에 실패한 경우 일시적인 네트워크 문제나 내부적인 에러일 수 있으므로 c.queue.Add()를 통해 다시 큐에 넣고 다시 시도하도록 한다. 만약에 정상적으로 처리되었다면 c.queue.Forget()를 통해 해당 이벤트를 큐에서 삭제한다.
여기서 조금 주의해야할 점이 있다면 성공적으로 processing이 된 이벤트에 대해서는 반드시 c.queue.Forget()을 호출해주어야 한다. 이는 RateLimitingQueue의 인터페이스인데 이를 호출해주지 않으면 적당한 back-off 시간이 지난 뒤에 해당 이벤트가 다시 큐에 추가된다.
type RateLimiter interface {
...
// Forget indicates that an item is finished being retried. Doesn't matter whether its for perm failing
// or for success, we'll stop tracking it
Forget(item interface{})
...
}더불어 defer c.queue.Done(item)에서 확인할 수 있다시피 processing한 이벤트에 대해서 반드시 c.queue.Done()을 호출해주어야 다음번에 같은 객체에 대해서 다시 처리할 수 있다.
Sync Custom Resource By Domain Logic
이제 변화가 생긴 custom resource에 대해서 도메인 로직에 따라서 싱크를 맞춰주어야 한다.
func (c *Controller) syncHandler(key string) error {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
utilruntime.HandleError(fmt.Errorf("invalid resource key: %s", key))
return nil
}
logger, err := c.loggerLister.Loggers(namespace).Get(name)
if err != nil {
if errors.IsNotFound(err) {
utilruntime.HandleError(fmt.Errorf("logger '%s' in work queue no longer exists", key))
return nil
}
return err
}
...
}이전에도 언급했지만 이벤트의 대상이 되는 키 값은 namespace와 resource name으로 구성되어있다고 했다. 그렇기 때문에 namespace와 name을 이용해서 해당 resource를 찾기 위해서 키 값을 파싱한다.
loggerLister를 통해서 키 값에 해당되는 resource를 조회하는 것을 살펴볼 수 있다.
에러 핸들링에서 주목해야할 점이 있다. errors.IsNotFound 인 경우 caller 함수, 즉 상위 함수로 에러를 던지고 있지 않은데 이는 존재하지 않는 리소스를 다시 큐에 넣지 않기위해서이다.
일반적으로 싱크 과정에서 에러가 발생하면 컨트롤러는 일시적인 장애가 발생했다고 판단해 다시 큐에 넣도록 설계하게 된다. 그렇기 때문에 다시 싱크가 필요한 resource에 대해서만 싱크 과정에서 에러가 발생하였다면 상위로 에러를 던져야 한다.
loggerName := logger.Spec.Name
if loggerName == "" {
// We choose to absort the error here as the worker would requeue the
// resource otherwise. Instead, the next time the resource is updated
// the resource will be enqueued again.
utilruntime.HandleError(fmt.Errorf("%s: deployment name must be specified", key))
return nil
}해당 코드 블럭을 보면서 느낄 수 있겠지만 위의 코드는 우리가 이전에 정의한 custom resource에 따라서 얼마든지 달라질 수 있다.
가령 custom resource에 다른 필드들이 존재한다면 해당 필드 값에 대해서 특별한 검증 로직을 달 수도 있을 것이다.
// Get the deployment with the name specified in Worker.Spec
deployment, err := c.deploymentsLister.Deployments(logger.Namespace).Get(name)
// If the resource doesn't exist, we'll create it
if errors.IsNotFound(err) {
deployment, err = c.kubeclient.AppsV1().Deployments(logger.Namespace).Create(newDeployment(logger))
}
// If an error occurs during Get/Create, we'll requeue the item so we can
// attempt processing again later. This could have been caused by a temporary
// network failure, or any other transient reason.
if err != nil {
return err
}
// If the Deployment is not controlled by this Worker resource, we should log
// a warning to the event recorder and return error message.
if !metav1.IsControlledBy(deployment, logger) {
msg := fmt.Sprintf("Resource %q already exists and is not managed by Logger", deployment.Name)
c.recorder.Event(logger, corev1.EventTypeWarning, "ErrResourceExists", msg)
return fmt.Errorf(msg)
}이 코드가 CRD의 핵심을 보여준다고 생각하는데 바로 Kubernetes의 확장성을 살펴볼 수 있는 부분이기 때문이다.
우리가 정의한 Logger는 그 자체로 존재하는 것이 아니라 기존에 Kubernetes에서 제공해주는 core resource (여기서는 Deployment)를 이용해서 새로운 resource를 만든 것이다. 좀 더 특별한 기능을 하는 한 단계 더 추상화된 resource로 볼 수도 있다.
// Get the deployment with the name specified in Worker.Spec
deployment, err := c.deploymentsLister.Deployments(logger.Namespace).Get(name)
// If the resource doesn't exist, we'll create it
if errors.IsNotFound(err) {
deployment, err = c.kubeclient.AppsV1().Deployments(logger.Namespace).Create(newDeployment(logger))
}여기서 Logger의 name과 namespace에 해당하는 Deployment가 없다면 newDeployment()를 통해서 새로 생성하고 있는데 newDeployment()를 잠깐 살펴보면
func newDeployment(logger *v1.Logger) *appsv1.Deployment {
labels := map[string]string{
"app": "user_activity_logger",
"name": logger.Spec.Name,
}
return &appsv1.Deployment{
ObjectMeta: metav1.ObjectMeta{
Name: logger.Spec.Name,
Namespace: logger.Namespace,
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(logger, loggerv1.SchemeGroupVersion.WithKind("Logger")),
},
},
Spec: appsv1.DeploymentSpec{
Replicas: logger.Spec.Replicas,
Selector: &metav1.LabelSelector{
MatchLabels: labels,
},
Template: corev1.PodTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
Labels: labels,
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{
{
Name: logger.Spec.Name,
ImagePullPolicy: corev1.PullNever,
Image: loggerDockerImage,
Args: []string{
logger.Spec.Name,
strconv.Itoa(logger.Spec.TimeInterval),
},
},
},
},
},
},
}
}OwnerReferences 필드에서 현재 처리되고 있는 Logger와 새로 생성될 Deployment의 종속관계가 설정되고 있다. 추후에 이를 통해 현재 Deployment가 orphan 상태인지 아닌지도 판별할 수 있다.
그 외에 눈여겨 볼 부분은 어떻게 Logger custom resource의 도메인 특화된 property들을 어떻게 core resource나 application service에 매핑시키는지를 주목할만하다.
Logger의 Name 필드의 경우는 Deployment나 Container Name 필드에 매핑되는데 이는 이후에 Logger의 이름으로 해당 Logger와 연결된 Deployment를 조회하는데 도움을 준다.
그리고 TimeInterval과 같은 필드는 컨테이너의 Args 필드로 주입되는 것을 확인할 수 있는데 이를 통해서 Logger 리소스를 생성하는 Actor는 활동 로그 수집 시간 간격을 변경하는 것과 같이 로깅 어플리케이션의 동작 방식을 변경할 수 있다.
Sync Only When Deployment is owned by Custom Resource
if !metav1.IsControlledBy(deployment, logger) {
msg := fmt.Sprintf("Resource %q already exists and is not managed by Logger", deployment.Name)
c.recorder.Event(logger, corev1.EventTypeWarning, "ErrResourceExists", msg)
return fmt.Errorf(msg)
}이전에 살펴보았던 OwnerReferences 필드를 이용해 종속 관계를 판단하고 있는 부분이다. 만약에 Logger Name에 해당하는 Deployment가 존재한다 하더라도 만약에 Logger와 종속관계를 맺고 있지 않다면 event recorder를 통해 경고 이벤트를 기록하고 에러를 리턴한다.
에러를 리턴한다는 것은 해당 키 값을 다시 큐에 넣겠다는 의미이고 이는 이러한 상황을 일시적인 문제라고 보고 있는 것이다. 예를 들어 이전에 동일한 Name으로 생성했던 유저 활동 로거를 삭제했는데 클러스터의 성능이 좋지 않든 네트워크의 상황이 좋지 않든 어떤 이유로 아직 이전에 삭제한 로거에 종속되어있던 Deployment를 아직 삭제를 못했다. 그리고 곧이어 같은 이름으로 유저 활동 로거를 생성했다.
이와 같은 상황이라면 언젠가는 삭제되어야할 이전 Deployment가 삭제될 것이고 그렇다면 문제 상황은 해결될 것이다.
// IsControlledBy checks if the object has a controllerRef set to the given owner
func IsControlledBy(obj Object, owner Object) bool {
ref := GetControllerOf(obj)
if ref == nil {
return false
}
return ref.UID == owner.GetUID()
}
// GetControllerOf returns a pointer to a copy of the controllerRef if controllee has a controller
func GetControllerOf(controllee Object) *OwnerReference {
for _, ref := range controllee.GetOwnerReferences() {
if ref.Controller != nil && *ref.Controller {
return &ref
}
}
return nil
}// NewControllerRef creates an OwnerReference pointing to the given owner.
func NewControllerRef(owner Object, gvk schema.GroupVersionKind) *OwnerReference {
blockOwnerDeletion := true
isController := true
return &OwnerReference{
APIVersion: gvk.GroupVersion().String(),
Kind: gvk.Kind,
Name: owner.GetName(),
UID: owner.GetUID(),
BlockOwnerDeletion: &blockOwnerDeletion,
Controller: &isController,
}
}위의 코드는 리소스 간의 ownership을 판단하는 코드이고 아래 코드는 ownership을 생성하는 부분이다. 둘다 Kubernetes go-client 레포지토리에서 가져왔다.
NewControllerRef 함수는 이전에 살펴봤던 newDeployment() 함수에서 사용된다. 이 때 생성된 Deployment의 OwnerReferences에는 Logger 리소스의 UID가 들어가게된다.
그리고 IsControlledBy 함수는 syncHandler()에서 호출되는 함수인데 이 때 Deployment의 owner UID와 Deployment의 owner로 추정되는 Logger의 UID를 비교함으로써 ownership을 판단하게 된다.
Kubernetes의 UID에 대한 더욱 자세한 설명은 여기에서 확인할 수 있다.
Execute Logger Controller
이제 우리가 만든 Controller를 어떻게 실행하고 Custom resource와 어떤식으로 인터렉션하는지 알아보자.
우선은 간단한 테스트 용도이니 minikube를 띄우고 minikube 클러스터에 Logger Controller와 Logger를 생성해보자.
Create Service Docker Image
가장 먼저 Controller가 관리할 서비스를 도커 이미지로 만들어야한다. 우리가 이전에 만들어 놓은 Dockerfile을 이용할 것이다. 이 때 주의해야할 것은 도커 이미지의 이름을 이전에 살펴보았던 newDeployment() 함수의 Image 필드의 이름과 동일해야한다는 것이다.
docker build -t user_activity_logger:latest .Create CustomResourceDefinition
다음으로 해야할 일은 클러스터에 Logger custom resource 정의에 대해 알려줘야하는데 이를 통해 클러스터는 해당 Logger resource를 어떻게 생성해야하는지 알게 된다.
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: loggers.example.com
spec:
group: example.com
versions:
- name: v1
served: true
storage: true
names:
kind: Logger
plural: loggers
scope: Namespaced
validation:
openAPIV3Schema:
required: ["spec"]
properties:
spec:
required: ["name", "timeInterval"]
properties:
name:
type: "string"
minimum: 1
timeInterval:
type: "integer"
minimum: 1custom resource 정의는 Kubernetes에서 제공해주는 CustomResourceDefinition를 통해서 하게 되는데 custom resource에 대한 정의도 Kubernetes에서는 또 하나의 resource이다.
spec.group, spec.versions 의 경우 처음에 code auto-gen을 할 때 명시해주었던 그룹과 버전을 써주도록한다.
그리고 validation 필드에서 Logger resource를 생성하기 위해 필수적으로 명시해야할 필드들을 나열할 수 있다. validation 필드에 들어간 필드들은 resource를 생성할 때 명시해주지 않으면 생성할 수 없다는 에러 메세지를 보여준다.
이 경우는 name과 timeInterval 모두 필수적으로 액터가 명시해주어야하는 필드라 생각하고 Replicas는 그렇지 않다고 생각하여 Replicas를 제외한 필드들을 validation 필드에 적어주었다.
kubectl apply -f artifacts/crd/logger.yamlcustom resource에 대한 정의를 마쳤다면 해당 CustomResourceDefinition resource를 클러스터에 생성하자.
Run Controller
go run ./cmd/main.go다음으로 우리가 만들었던 Logger controller를 실행시킨다. 이 순간부터 Logger controller는 클러스터로부터 Logger 리소스에 변화가 생길 때마다 이벤트 핸들러가 실행되며 이벤트 핸들러는 현재 클러스터에 떠있는 Logger resource의 상태와 desired state를 비교한 후 desired state로 만들기 위해 Logger controller가 싱크하는 작업을 수행하게 된다.
Deploy UserActivityLogger
이제 정말로 유저 활동 로거 서비스를 배포할 단계이다.
apiVersion: example.com/v1
kind: Logger
metadata:
name: example-logger
spec:
name: example-logger
timeInterval: 3000
replicas: 1이전에 생성했던 Logger CustomResourceDefinition 덕분에 클러스터는 kind: Logger를 이해할 수 있고 어떻게 리소스를 생성해야할지 안다.
kubectl apply -f artifacts/logger/example.yaml기억해야할 것은 여기서 apply를 한다고 해서 직접적으로 Logger resource를 생성하는 것이 아니라는 것이다. 우리는 클러스터에 desired state를 변경시키는 것이다. Logger controller는 이렇게 바뀐 desired state의 변화를 감지하고 desired state를 만들기 위해 동작한다.
이와 같은 상황에서는 Logger controller가 Logger created와 같은 이벤트를 감지했을 것이고 이벤트에서 생성하고자하는 Logger의 정보를 받아 싱크 작업을 수행했을 것이다.
정리하며
Controller에 대한 설명은 deep-dive는 한다면 짧은 책으로 낼 수 있을 정도로 길어질 수 있을 거 같다. 그만큼 제대로 controller를 구현하기 위해서는 디테일하게 알아야하는 부분이 많고, 어떤 식으로 동작하는지 이해하기 위해서는 봐야하는 소스코드들이 상당하기 때문인 것 같다.
이 글을 쓰면서도 어느 정도까지 써야하나 상당히 고민이 많았다. 너무 자세하게 쓰자니 시간도 많이 걸리고 글이 이해하기 어려워지고 장황해진다. 그렇다고 추상적으로 쓰면 어떻게 동작하는지 정확히 설명하기가 어려울 거 같았다.
그래서 우선 이 정도로 설명하게 참고할만한 Kubernetes client 코드들은 아래에 Appendix로 달아놓기로 결정했다.
이번 포스팅에서 사용된 예제의 소스코드는 여기에서 확인할 수 있다.
더 읽어볼만한 글들
이 글을 쓰면서 소개하지 못했던, 그렇지만 한 번 읽어보면 좋을만한 글들을 정리하려고 한다.
Kubernetes Developer Guidelines
해당 글에서는 Kubernetes controller를 작성할 때 어떤 식으로 설계해야하는지 이 글에서 설명하지 못했던 디테일한 부분을 소개하고 있다. 혹시 controller를 만들어야할 일이 있다면 한 번 읽어보는 것을 권장한다.
Appendix
Create Queue Event
// MetaNamespaceKeyFunc is a convenient default KeyFunc which knows how to make
// keys for API objects which implement meta.Interface.
// The key uses the format <namespace>/<name> unless <namespace> is empty, then
// it's just <name>.
//
// TODO: replace key-as-string with a key-as-struct so that this
// packing/unpacking won't be necessary.
func MetaNamespaceKeyFunc(obj interface{}) (string, error) {
if key, ok := obj.(ExplicitKey); ok {
return string(key), nil
}
meta, err := meta.Accessor(obj)
if err != nil {
return "", fmt.Errorf("object has no meta: %v", err)
}
if len(meta.GetNamespace()) > 0 {
return meta.GetNamespace() + "/" + meta.GetName(), nil
}
return meta.GetName(), nil
}여기에서 큐에 들어가는 이벤트가 어떻게 만들어지는지 확인할 수 있다.
Create Deployment Informer
// NewFilteredDeploymentInformer constructs a new informer for Deployment type.
// Always prefer using an informer factory to get a shared informer instead of getting an independent
// one. This reduces memory footprint and number of connections to the server.
func NewFilteredDeploymentInformer(client kubernetes.Interface, namespace string, resyncPeriod time.Duration, indexers cache.Indexers, tweakListOptions internalinterfaces.TweakListOptionsFunc) cache.SharedIndexInformer {
return cache.NewSharedIndexInformer(
&cache.ListWatch{
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.AppsV1().Deployments(namespace).List(options)
},
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.AppsV1().Deployments(namespace).Watch(options)
},
},
&appsv1.Deployment{},
resyncPeriod,
indexers,
)
}해당 코드는 Deployment resource type에 대한 informer를 생성하는 부분이다. 여기를 살펴봤던 이유는 informer와 lister의 관계에 대해서 알고 싶어서이다.
NewSharedIndexInformer 함수 첫번째 인자로 cache.ListWatch가 주입되는데 해당 구조체 안에 있는 이벤트 핸들러에서 자신이 어떤 것을 듣고 있을지 구체적인 타입이 결정된다. cache.ListWatch 그 자체로는 자신이 어떤 것을 리스닝할지 모른다.
결론적으로 informer가 lister를 생성할 수 있는 관계를 가진다.
func (f *deploymentInformer) Lister() v1.DeploymentLister {
return v1.NewDeploymentLister(f.Informer().GetIndexer())
}Record Event to Sink
// StartRecordingToSink starts sending events received from the specified eventBroadcaster to the given sink.
// The return value can be ignored or used to stop recording, if desired.
// TODO: make me an object with parameterizable queue length and retry interval
func (eventBroadcaster *eventBroadcasterImpl) StartRecordingToSink(sink EventSink) watch.Interface {
eventCorrelator := NewEventCorrelatorWithOptions(eventBroadcaster.options)
return eventBroadcaster.StartEventWatcher(
func(event *v1.Event) {
recordToSink(sink, event, eventCorrelator, eventBroadcaster.sleepDuration)
})
}Event recorder가 자신이 기록하는 이벤트를 어디로 전송하는지 궁금해서 살펴본 부분이다.
내부적으로 event broadcaster는 recordToSink 함수를 호출하는데 여기서 표현되는 sink는 이벤트 저장소를 추상화한 개념이다. 처음에는 어떤 파일이나 데이터베이스에 기록되나싶었는데 실제로는 sink 구현체가 Kubernetes client를 가지고 있고 해당 client가 클러스터로 API 통신을 한다.
// Create takes the representation of a event and creates it. Returns the server's representation of the event, and an error, if there is any.
func (c *events) Create(event *v1.Event) (result *v1.Event, err error) {
result = &v1.Event{}
err = c.client.Post().
Namespace(c.ns).
Resource("events").
Body(event).
Do().
Into(result)
return
}events는 Event와 인터렉션을 하는 책임을 가지고 있는 객체이고 sink 구현체가 events를 가지고 있는 구조이다.