Spring Batch Scope & Testing
Spring Batch를 이용한 작업을 두 달 전쯤부터 꽤 많이 그리고 오랫동안 했었는데 배치와 관련해서 좋은 레퍼런스를 찾기 힘들었던 기억이 있다.
기본적인 것들은 쉽게 찾아볼 수 있지만 배치 테스트 케이스나 몇 가지 특수한 케이스에 대해서는 찾아보기가 어려웠다. 또한 Spring Batch 프레임워크의 도메인때문에 몇 가지 지식이 없었을 때 내가 만든 배치가 내가 기대했던대로 동작하지 않는 허다했다. 혹은 잘 동작하는 것 같았지만 그렇지 않을 때도 있었다.
간단해보이지만 제대로 이해하지 못하면 잘못 프로그램을 작성할 수 있겠다는 생각이 들었다. 이번 포스팅에서는 두어달간 작업하면서 경험했던 것들에 대해서 작성해보고자 한다.
이번 글에서 다룰 내용은 아래와 같다.
- Spring Batch 기본적인 것에 대해서는 이야기하지 않을 것이다. Reader, Writer, Processor 등 기본적인 것에 대해서는 설명하지 않는다.
- 배치 스케쥴러에 대해서 설명하지 않는다.
- Spring Batch를 이용하면서 몇 가지 특수했던 케이스 대해서 설명한다.
- 그 과정에서 Scope 등 Spring Batch 프레임워크의 몇 가지 특성을 정리하고 관련해서 실수했던 부분에 대해서 소개하고자 한다.
- 배치 잡 테스트하는 방법에 대해서 설명한다.
HttpItemReader
이번에 Spring Batch를 사용하면서 spring-project의 Spring Batch 코드를 비롯해서 꽤 여러 코드를 살펴보았는데 좋은 레퍼런스를 찾지 못했던 케이스들이 몇 가지 있었다.
그 중 첫 번째는 HTTP를 이용하여 다른 서비스의 리소스를 Pagination을 이용하여 조회하는 경우이다. 요구사항을 정리하면 아래와 같을 것이다. 이해를 돕기 위해 GET /books?page=<number>&size=<number> 와 같이 책을 조회할 수 있는 API가 제공된다고 하자.
- API로부터 특정 리소스를 조회하여 첫 페이지부터 마지막 페이지의 리소스를 모두 읽어야 한다.
- 첫 페이지부터 마지막 페이지까지 읽어야하는데 마지막 페이지가 몇 페이지는 알지 못한다. 넘어오는 데이터가 없으면 마지막 페이지라고 가정한다.
한 가지 생각해야할 포인트는 배치가 조회하는 타겟 서비스는 현재 운영 중에 있기 때문에 책은 계속 추가되거나 삭제될 수 있다. 이 때 배치는 이러한 사실을 알 수 없기 때문에 배치는 자신이 동작할 때 타겟 서비스의 리소스 스냅샷을 찍는다고 생각해야한다.
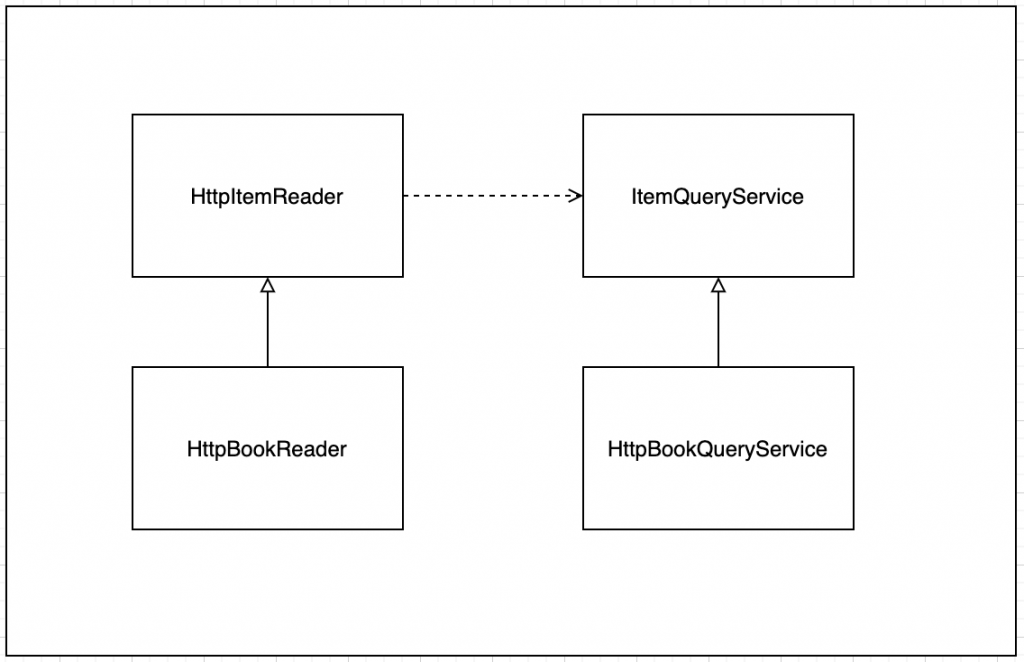
ItemQueryService 는 특정 리소스를 조회하는 역할에 집중하고 HttpItemReader는 ItemQueryService를 이용하여 배치 특성에 따라 리소스를 읽는 역할에 집중한다.
그리고 배치를 수행하는 도메인 객체에 대해서 구현체를 만든다.
ItemQueryService
public interface ItemQueryService<T> {
Page<T> findAll(Pageable pageable);
}
@Component
public class HttpBookQueryService implements ItemQueryService<Book> {
private RestTemplate restTemplate;
public HttpMemberStakingQueryService(
@Qualifier("bookService") RestTemplate restTemplate
) {
this.restTemplate = restTemplate;
}
@Override
public Page<Book> findAll(Pageable pageable) {
ResponseEntity<Pagination<BookData>> response = restTemplate.exchange(
format("/books?page=%d&size=%d", pageable.getPageNumber(), pageable.getPageSize()),
HttpMethod.GET,
null,
new ParameterizedTypeReference<Pagination<BookData>>() {}
);
List<Book> books = response.getBody().getData()
.stream()
.map(...)
.collect(toList());
...
return new PageImpl<>(stakings, pageable, totalCount);
}
static class BookData { ... }
}제네릭을 이용하여 조회하는 타겟 리소스와 무관한 인터페이스를 만들고 HTTP 도메인과 무관한 인자와 리턴 값을 주고 받아 일반적인 query service를 만든다.
HttpBookQueryService는 한 가지 예시로 작성해두었다. RestTemplate을 이용하여 타겟 BookService에서 리소스를 조회하는 부분이다.
HttpItemReader
public abstract class HttpItemReader<T> {
private final int chunkSize;
private ItemQueryService itemQueryService;
private int page;
private Iterator<T> iterator;
...
protect T doHttpRead() {
if (!shouldFetchFromApi()) {
return readItem();
}
Page<T> items = itemQueryService.findAll(PageRequest.of(page, chunkSize));
if (items == null) {
return null;
}
if (!items.hasContent()) {
return null;
}
return readItem(items.getContent());
}
private T readItem() {
if (!iterator.hasNext()) {
readyToFetchNextPage();
}
return iterator.next();
}
private T readItem(List<T> items) {
iterator = items.iterator();
return readItem();
}
private boolean shouldFetchFromApi() {
return iterator == null;
}
private void readyToFetchNextPage() {
iterator = null;
page += 1;
throw new ShouldFetchNextPageException();
}
}
public class BookReader extends HttpItemReader<Book> implements ItemReader<MemberStaking> {
public BookReader(Integer chunkSize, BookQueryService bookQueryService) {
super(chunkSize, bookQueryService);
}
@Override
public Book read() {
return doHttpRead();
}
}Spring Batch의 ItemReader는 아이템을 하나씩 넘겨줘야한다. 그리고 그것이 chunk size만큼 모였다면 그것을 한번에 ItemWriter로 전달한다.
그렇기 때문에 HTTP pagination으로 읽어들인 복수 개의 아이템들을 한 번에 하나씩 넘겨주어야하는데 그렇기 때문에 HttpItemReader가 내부에 iterator와 page라는 상태를 가질 수밖에 없게 되었다. :'(
우선 iterator에 아이템 있냐 없냐에 따라 현재 HttpItemReader가 페이지를 읽고 있는 중인지 아닌지를 판단한다. 만약에 페이지를 읽고 있는 중이라면 iterator의 다음 아이템을 읽는다.
만약에 페이지를 읽고 있는 중이 아니라면 QueryService를 통해서 다음 데이터를 읽어온다. 이 때 데이터가 존재하지 않는다면 타겟 서비스의 리소스를 모두 조회했다고 판단하고 return null을 통해서 ItemReader의 작업을 종료한다.
readItem()을 호출할 시점에 만약 현재 페이지의 아이템들을 전부 읽었다면 readyToFetchNextPage() 호출을 통해서 다음 페이지의 데이터를 읽기 위한 준비를 한다.
다음 페이지를 읽기 위한 트릭으로 readyToFetchNextPage()에서 예외를 던진다. ShouldFetchNextPageException 에러는 사전에 정의된 예외가 아니고 RuntimeException을 상속한 '아무 예외'이다.
만약 return null을 하게 된다면 Spring Batch는 아이템들을 전부 읽었다고 생각하고 ItemWriter로 데이터를 flush하거나 해당 배치 잡을 종료 시켜버린다.
@EnableBatchProcessing
@Configuration
public class BatchJobConfiguration {
...
@Bean
public Step bookQueryStep(@Qualifier("chunkSize") Integer chunkSize) {
return stepBuilderFactory.get("bookQueryStep")
.<Book, Book>chunk(chunkSize)
.reader(httpBookReader(chunkSize))
...
.faultTolerant()
.skipLimit(Integer.MAX_VALUE)
.skip(ShouldFetchNextPageException.class) // continue to read item when ShouldFetchNextPageException thrown
.build();
}
@Bean
@StepScope
public ItemReader<Book> httpBookReader(@Qualifier("chunkSize") Integer chunkSize) {
return new HttpBookReader(chunkSize, bookQueryService);
}
}HttpItemReader에서 던져진 예외는 배치 잡 bean을 생성하는 곳에서 핸들링된다. .skip(ShouldFetchNextPageException.class) 에서 해당 에러를 잡으면 로그만 찍고 다음 read()를 수행한다.
이를 이용해 HttpItemReader는 다음 페이지에 대한 리소스를 조회할 수 있다.
Spring Batch 상태 관리
Spring은 기본적으로 bean들이 singleton으로 어플리케이션이 시작할 때 등록되고 이것이 Spring bean의 default scope이다. 그리고 bean의 상태가 여러 로컬 스레드에서 공유된다. 그렇다면 우리가 만든 HttpItemReader의 page나 iterator와 같은 내부적인 상태가 다음번 배치가 구동될 때 공유되지 않을까하고 의문이 들 수 있다.
bean이 등록되는 config 클래스에서 @StepScope, @JobScope와 같은 어노테이션을 @Bean 어노테이션과 같이 붙이면 해당 bean은 배치 어플리케이션이 구동될 때 생성되는 것이 아니라 해당 job이나 step이 실행될 때마다 bean이 생성된다.
그렇기 때문에 스케쥴러에 의해 다음번 배치가 실행되면 bean들이 새로 생성되면서 내부 상태도 모두 초기화된다.
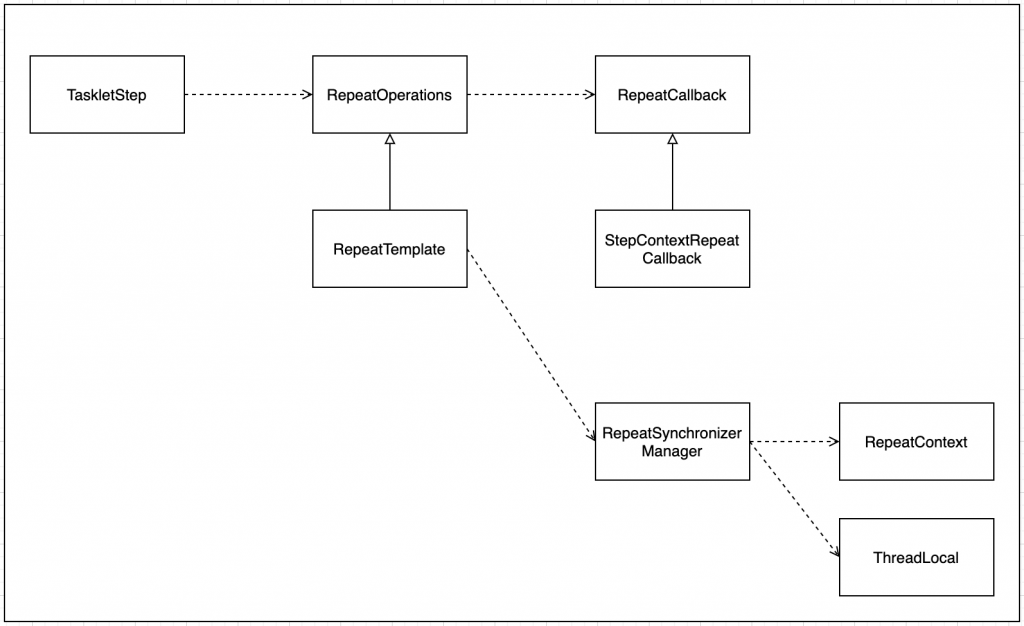
또한 Spring Batch 프레임워크 단에서 각 StepScope, JobScope 별로 ExecutionContext를 관리한다. 처음엔 이 부분이 bean 내부 상태 관리와 연관이 있나하고 유심히 살펴봤지만 사실 생각해보면 위에서 언급한 특성은 Spring bean의 특성이라고 할 수 있다.
ExecutionContext의 대표적인 예 중 하나가 RepeatContext이다. (Spring Batch Core 코드에 ExecutionContext 클래스는 없다.) RepeatContext는 ChunkProvider(ItemReader, ItemProcessor를 합쳐 추상화한 개념)가 얼마나 실행되었는지에 대한 정보를 담고있다. 코드를 살펴보면 RepeatContext는 단순히 Key/Value로 관리되는 자료구조이다.
Spring Batch Job을 구성하는 Step 내부에는 TaskletStep이 존재하고 Step이 실행될 때 해당 Step이 어디까지 진행되었나 기록하기 위해서 RepeatOperations을 이용한다. 내부를 살펴보면 Template/Callback 패턴으로 구현되어있는 것을 살펴볼 수 있다.
RepositoryItemReader
@StepScope을 붙이지 않아 발생했던 미묘한 버그에 대해서 소개하고자 한다.
@Bean
@StepScope
public RepositoryItemReader<Book> repositoryBookReader(@Qualifier("chunkSize") Integer chunkSize) {
return new RepositoryItemReaderBuilder<Book>()
.repository(bookRepository)
.methodName("findAllByCreatedAtBetweeen")
.arguments(timeProvider.startOfDay(), timeProvider.now())
.pageSize(chunkSize)
.sorts(Collections.singletonMap("created_at", Sort.Direction.DESC))
.name("repositoryBookReader")
.build();
}RepositoryItemReader를 이용하면 JPA와 Spring Batch를 예쁘게 연결시킬 수 있다. 만약 위의 코드에서 @StepScope이 없다면 문제가 될 부분은 어디일까?
바로, .arguments(timeProvider.startOfDay(), timeProvider.now()) 부분이다.
왜 일까? 다음과 같은 상황을 생각해보자.
Batch Start
Job A
Job B <- 여기서 repositoryBookReader가 동작
Batch Finish하나의 스케쥴러에서 Job A와 Job B가 순차적으로 실행된다. Job B는 Job A의 결과물을 이용해서 어떤 작업을 수행한다고 하자. repositoryBookReader는 Job B의 Step 중 하나에서 사용되는 ItemReader이다.
repositoryBookReader는 오늘 시작부터 '현재'까지 저장된 아이템들을 조회한다. 문제는 '현재'가 언제냐인 것인데 우리가 기대한 '현재'는 Job A가 끝나고 Job B가 시작되고 자신의 Step이 실행되는 시점이다.
하지만 우리는 @StepScope을 명시하지 않았기 때문에 repositoryBookReader는 'Batch Start' 시점에 bean이 생성되어버리고 '현재'라는 시간도 'Batch Start' 시점이 되어버린다. 따라서 Job A의 결과물을 Job B에서 읽어들일 수 없다.
@StepScope을 명시한다면 repositoryBookReader는 Job B가 시작되고 Step이 실행될 때 bean이 생성되기 때문에 '현재'는 Job B가 실행되는 시점이 된다.
Spring Batch Job E2E Testing
Spring Batch는 Step, Job 등 여러 수준에서 테스트할 수 있다. 그 중에서 Job 레벨에서 테스트하는 방법에 대해서 소개하고자 한다.
우선 Spring Batch를 테스트를 도와주는 라이브러리가 별도로 존재하는데 이것를 gradle이나 maven 설정파일에 추가한다.
@TestConfiguration
@EnableBatchProcessing
public class BatchJobTestConfiguration {
@Profile("test")
@Bean
@Qualifier("chunkSize")
public Integer batchContext() {
return 3;
}
@Bean
@Qualifier("bookReadJob")
JobLauncherTestUtils bookReadJobUtils() {
return new JobLauncherTestUtils() {
@Override
@Autowired
public void setJob(@Qualifier("bookReadJob") Job job) {
super.setJob(job);
}
};
}
}배치 Job은 JobLauncherTestUtils을 이용해서 JUnit 테스트를 진행한다. BatchJobTestConfiguration 클래스에 Job별로 JobLauncherTestUtils을 만들어주고 setJob에 테스트하고자하는 Job bean을 주입한다.
만약 테스트하고 싶은 Job이 추가된다면 BatchJobTestConfiguration에 다른 이름의 @Qualifier로 Job과 JobLauncherTestUtils을 정의해주면 된다.
@ActiveProfiles("test")
@RunWith(SpringRunner.class)
@EnableAutoConfiguration
@SpringBootTest(classes = {BatchJobTestConfiguration.class})
@DirtiesContext(classMode = DirtiesContext.ClassMode.AFTER_CLASS)
public class BookReadJobTests {
@Autowired
@Qualifier("bookReadJob")
private Job job;
@Autowired
@Qualifier("bookReadJobUtils")
private JobLauncherTestUtils jobLauncherTestUtils;
@MockBean
private BookQueryService bookQueryService;
@Autowired
private BookRepository bookRepository;
// @Before, @After
@Test
public void readingBookTest() throws Exception {
// mock data setup
JobLauncher jobLauncher = jobLauncherTestUtils.getJobLauncher();
JobExecution jobExecution = jobLauncher.run(
job,
new JobParametersBuilder().addLong("time", System.currentTimeMillis()).toJobParameters()
);
ExitStatus exitStatus = jobExecution.getExitStatus();
assertThat(exitStatus.getExitCode()).isEqualTo("COMPLETED");
// database assertions
}
}BatchJobTestConfiguration에서 생성한 내가 테스트하고 싶은 Job bean과 JobLauncherTestUtils bean을 정의하고 테스트 클래스에서 주입받는다. BookQueryService의 경우 HTTP 통신을 직접하고 싶지는 않기 때문에 mock 객체로 정의한다.
하나 짚고 넘어갈 부분은 jobLauncher.run() 에 두번째 인자로 주어지는 JobParameters에 대해서다. JobLauncher는 새로운 JobInstance로 해당 배치 Job을 실행시키기 위해서는 다른 JobParameter가 주어져야 한다. 우리는 만약 테스트가 여러개 있을 경우 각 테스트 케이스마다 새로운 Job 인스턴스로 테스트하고 싶다. 그렇기 때문에 매 실행마다 JobParameter가 달라질 수 있도록 코드를 작성하였다.
사실 코드는 크게 설명할 것이 없다. 테스트 코드를 써넣은 것은 여러 군데에서 찾은 예제 테스트 코드나 레퍼런스 테스트 코드가 제대로 동작하지 않았고 위와 같이 BatchJobTestConfiguration을 작성하고 테스트 코드를 작성해야 제대로 동작했기 때문이다.
Appendix
SimpleChunkProvider
public class SimpleChunkProvider<I> implements ChunkProvider<I> {
@Override
public Chunk<I> provide(final StepContribution contribution) throws Exception {
final Chunk<I> inputs = new Chunk<>();
repeatOperations.iterate(new RepeatCallback() {
@Override
public RepeatStatus doInIteration(final RepeatContext context) throws Exception {
I item = null;
Timer.Sample sample = Timer.start(Metrics.globalRegistry);
String status = BatchMetrics.STATUS_SUCCESS;
try {
item = read(contribution, inputs);
}
catch (SkipOverflowException e) {
// read() tells us about an excess of skips by throwing an
// exception
status = BatchMetrics.STATUS_FAILURE;
return RepeatStatus.FINISHED;
}
...
}
});
return inputs;
}
}- Spring Batch는 내부적으로 SimpleChunkProvider를 통해서 ItemReader와 ItemProcessor의 작업을 수행한다. ChunkProvider는 이 두 개의 작업을 추상화한 인터페이스로 생각할 수 있다. ChunkProcessor에서 ChunkProvider에서 제공해주는 아이템의 묶음들을 가공한다.
FaultTolerantChunkProvider
public class FaultTolerantChunkProvider<I> extends SimpleChunkProvider<I> {
@Override
protected I read(StepContribution contribution, Chunk<I> chunk) throws Exception {
while (true) {
try {
return doRead();
}
catch (Exception e) {
if (shouldSkip(skipPolicy, e, contribution.getStepSkipCount())) {
// increment skip count and try again
contribution.incrementReadSkipCount();
chunk.skip(e);
if (chunk.getErrors().size() >= maxSkipsOnRead) {
throw new SkipOverflowException("Too many skips on read");
}
logger.debug("Skipping failed input", e);
}
else {
if (rollbackClassifier.classify(e)) {
throw new NonSkippableReadException("Non-skippable exception during read", e);
}
logger.debug("No-rollback for non-skippable exception (ignored)", e);
}
}
}
}
}- FaultTolerantChunkProvider는 SimpleChunkProvider 클래스의
read()를 재정의했다. 위의 코드에서 어떻게 특정 예외가 발생했을 때 skip하는지 로직을 살펴볼 수 있다.
ExecutionContext
public abstract class AttributeAccessorSupport implements AttributeAccessor, Serializable {
/** Map with String keys and Object values. */
private final Map<String, Object> attributes = new LinkedHashMap<>();
...
}
public class SynchronizedAttributeAccessor implements AttributeAccessor {
/**
* All methods are delegated to this support object.
*/
AttributeAccessorSupport support = new AttributeAccessorSupport() {
/**
* Generated serial UID.
*/
private static final long serialVersionUID = -7664290016506582290L;
};
}
public class RepeatContextSupport extends SynchronizedAttributeAccessor implements RepeatContext {
}- ExecutionContext를 관리하는 자료구조 및 구현체들.