Kubernetes Resource and QoS Concept
이번 포스팅에서는 Kubernetes에서 사용하는 resource에 대한 개념과 resource와 관련해서 잘 알고 있지 못하면 큰 문제를 일으킬 수도 있는 Quality of Service라는 것에 대해서 알아본다.
Managing Resources for Containers
Pod를 띄울 때 우리는 Pod에 속해있는 Container가 얼마만큼의 resource를 가질지 선택적으로 명시할 수 있다. resource 종류에는 다른 것들도 있지만 가장 대표적인 것은 CPU와 메모리이다.
Container의 resource request를 명시하면 스케쥴러는 이 정보를 바탕으로 어떤 노드에 Pod를 배치시킬지를 결정한다. 그리고 Container의 resource limit을 명시하면 kubelet은 런타임 상태의 Container가 명시된 resource의 limit 이상을 사용할 수 없도록 강제한다. 또한 kubelet은 request에 명시한 resource만큼을 해당 Container가 사용할 수 있도록 미리 예약을 해둔다.
Resource Requests and limits
만약 node가 Pod을 배정받고 resource를 할당해주고도 자신에게 남은 resource가 있다면 배정된 Pod이 자신이 요청(request)한 resource보다 더욱 많은 resource를 사용할 수 있다. 하지만 그 값은 limit을 넘지 못한다.
예를 들어, 어떤 Container의 requests.memory 필드에 값을 256MiB를 설정했고 해당 Pod을 8GiB 메모리를 가진 node에게 배정을 했을 때 (그리고 그 node에 다른 Pod이 없으면) 배정한 Container는 자신이 설정한 256MiB보다 더욱 많은 메모리를 사용할 수 있다.
만약 어떤 Container의 limit.memory 값에 4GiB를 설정했다면 kubelet과 containe runtime이 해당 컨테이너가 그 이상의 메모리를 사용하지 못하도록 강제한다. 예를 들어 Container에서 실행되고 있는 프로세스가 limit에 설정된 값보다 많은 메모리를 사용하려고 한다면 시스템 커널이 해당 프로세스를 OOM 에러와 함께 종료시킨다.
resource limit에 대해 container runtime은 해당 Container에 제재를 가하는데 이 때 limit이 넘었는지 체크하는 방법은 여러가지로 할 수 있다. 한 가지 방법은 해당 Container가 한 번이라도 limit을 넘었을 때 제재를 가하는 방식이 있고 다른 방식 중 하나는 특정 시간 이상 limit 값을 넘었을 때 제재를 가할 수도 있다.
이런 상황이 궁금할 수도 있다. 만약 Container에 메모리 limit은 설정했는데 request 값을 설정하지 않았다면 어떤 일이 벌어질까? Kubernetes는 자동으로 limit에 설정한 값만큼 request 값을 설정한다. 이는 CPU에 대해서도 마찬가지이다.
Resources in Kubernetes
Kubernetes에서 각 Pod에 할당할 수 있는 resource 타입 중 가장 대표적인 것은 CPU와 메모리가 있다. 각각에 대해서 살펴보면 아래와 같다.
CPU
CPU에 대한 request와 limit 값은 cpu unit이라는 단위를 가진다. 1 cpu는 Kubernetes에서 1vCPU/Core로 생각할 수 있다. 만약 0.5라는 값으로 설정한다면 이는 500m와 같은 값을 나타내며 500 밀리 cpu를 가진다고 생각할 수 있다.
그리고 이 값은 상대적인 값이 아니다. 무슨 말이냐면 single-core나 dual-core를 가진 node에 0.5이라는 CPU request, limit 값을 설정한다면 코어의 수에 따라 비례하는 값이 아니라 두 개의 node에 대해서 동일한 CPU를 할당한다는 뜻이다.
Memory
메모리에 대한 request와 limit 값은 바이트 단위를 가진다. 이 값은 정수로 나타내야하며 숫자 뒤에 E, P, T, G, M, K와 같은 접미어가 붙을 수도 있다. 각각은 Ei, Pi, Ti, Gi, Mi, Ki와 동일한 의미를 가진다.
How Pods with resource requests are scheduled
우리가 Pod을 생성할 때 Kubernetes 스케쥴러는 어떤 node에 Pod을 띄울지를 결정한다. 각각의 node는 각각의 resource에 대해서 최대 수용량이 있을 것이다.
스케쥴러는 각 노드에 스케쥴된 Container의 각 resource 타입의 총합이 해당 node의 최대 수용량을 각 resource 타입별로 넘지 않도록 만든다. 그래서 어떤 node가 CPU가 넉넉히 남는다고해서 해당 node에 Pod이 스케쥴링된다는 보장을 할 수 없다. 왜냐하면 다른 타입의 resource가 부족할 수도 있기 때문이다.
이러한 설계는 node에 배정된 Pod들이 피크 타임 때 resource가 부족한 상황을 방지하는데 도움을 준다.
How Pods with resource requests are run
우리가 Pod을 생성할 때 Kubernetes 스케쥴러는 어떤 node에 Pod을 띄울지를 결정한다. 각각의 node는 각각의 resource에 대해서 최대 수용량이 있을 것이다.
스케쥴러는 각 노드에 스케쥴된 Container의 각 resource 타입의 총합이 해당 node의 최대 수용량을 각 resource 타입별로 넘지 않도록 만든다. 그래서 어떤 node가 CPU가 넉넉히 남는다고해서 해당 node에 Pod이 스케쥴링된다는 보장을 할 수 없다. 왜냐하면 다른 타입의 resource가 부족할 수도 있기 때문이다.
이러한 설계는 node에 배정된 Pod들이 피크 타임 때 resource가 부족한 상황을 방지하는데 도움을 준다.
How Pods with resource limits are run
Pod에 설정된 resource request와 limit이 어떻게 영향을 미치는지를 알아보기 위해서는 Compressible/Incompressible resource에 대해서 아는 것이 도움이 된다.
Kubernetes에서 Comressible한 resource 중 대표적인 것은 바로 CPU이다. Compressible resource는 Pod이 그 값을 초과하려고 하면 자신이 사용할 수 있는 resource에 한계가 있기 때문에 병목이 걸린다. 왜냐하면 필요한 값보다 자신이 사용할 수 있는 resource가 적기 때문이다.
반면에 Incompressible resource에 대표적인 것 중 하나는 메모리가 있는데 Incompressible resource의 경우는 Pod이 그 사용량을 초과하려고하면 해당 Pod 내부 컨테이너의 커널에 의해 killed된다.
그래서 이를 정리하면 아래와 같은 상황이 나타날 수 있다.
- 만약 Container가 자신에게 설정된 메모리 limit보다 그 사용량을 초과했을 때 해당 Container는 종료될 수 있다. 만약 다시 시작할 수 있다면 kubelet은 해당 Container를 다시 실행시킨다.
- 만약 Container가 자신에게 설정된 메모리 request보다 그 사용량을 초과했을 때 Container는 자신이 배정된 node의 메모리가 부족하면 evicted된다.
- 만약 Container 자신에게 설정된 CPU limit을 특정 시간 이상 동안 넘는다하더라도 해당 Container는 죽지 않는다.
Quality of Service
Quality of Service(QoS)는 얼마나 해당 Pod이 클러스터내에서 서비스를 잘해줄지를 알려주는 하나의 값이다. QoS는 크게 세 가지 종류가 있는데 BestEffort, Burstable 그리고 Guarnteed가 있다. 순서대로 Kubernetes 클러스터가 생각하기에 서비스의 우선 순위가 높고, 만약 클러스터 전체에서 어떤 시스템이 자원이 부족하다고 하면 서비스 우선 순위가 가장 낮은 서비스부터 없앤다.
BestEffort, Burstable, Guarnteed에 대해서는 아래에서 자세히 살펴보려고 한다.
QoS는 Pod에 설정된 request, limits에 의해서 결정된다. 위에서 살펴보았듯이 request 값은 자신이 클러스터에 배포되었을 때 자신에게 얼마의 resource를 할당해줄지를 나타내는 값이고 limit 값은 해당 Pod이 클러스터에서 최대 얼마만큼의 resource를 사용할 수 있는지를 나타내는 값이다. 그리고 Pod의 스케쥴링은 limit이 아니라 request 값에 의해서 결정된다.
BestEffort
request, limit을 명시하지 않은 Pod은 BestEffort QoS를 가진다. 이렇게 Kubernetes에 명시적으로 request, limit을 명시하지 않으면 스케쥴러는 해당 Pod을 어떤 node에 스케쥴링해야할지 알지 못한다. 실제 운영 중인 클러스터를 구성 하는 node 중 어떤 node는 바쁠 것이고 어떤 것은 여유로울 것인데 새로 띄우려는 Pod이 얼마만큼의 resource request, limit을 필요한지 알지 못하기 때문에 스케쥴러는 추측해서 해당 Pod을 띄울 수밖에 없다.
이러한 Kubernetes 스케쥴러의 동작이 바로 BestEffort이다. 스케쥴러가 자신이 해당 Pod을 어디에 스케쥴해야할지 잘 알진 못하지만 알아서 최선의 선택을 해보겠다는 전략이다.
왜 BestEffort은 위험할까?
아래와 같은 상황을 생각해보자. 예를 들어 우리는 한 개의 node로 구성된 클러스터를 운영하고 있고 이 node에는 이미 운영 중인 여러 개의 Pod이 돌고 있다. 그리고 각각의 Pod은 request, limit이 설정되어있어 자신에게 할당된 resource를 이용해서 잘 동작하고 있다.
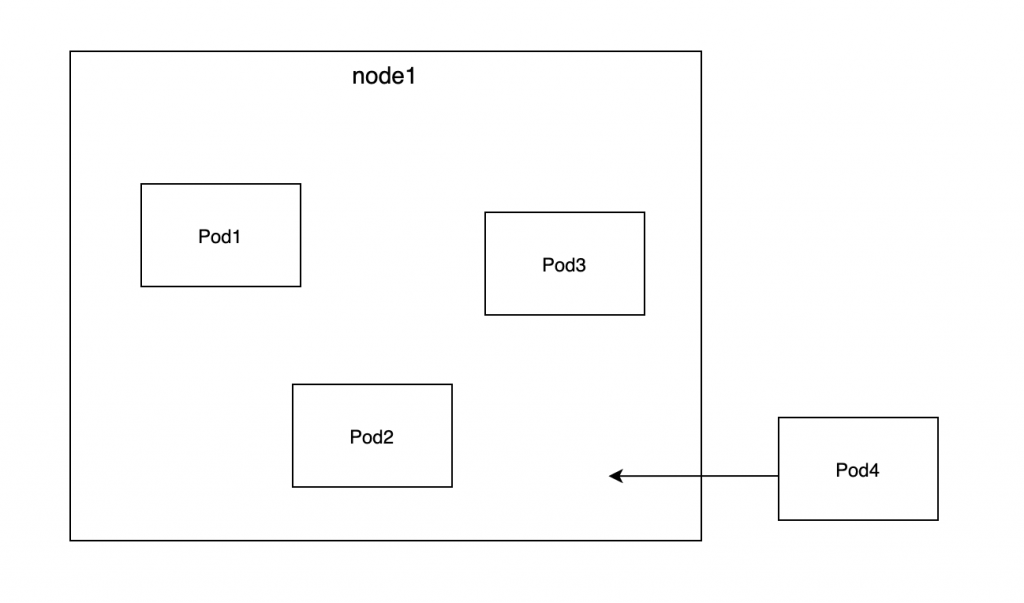
그런데 이제 여기에 request, limit이 설정되지 않은 Pod을 새로 띄우려고 한다. Kubernetes 스케쥴러는 일단 이 Pod을 띄울 node가 하나밖에 없기 때문에 이 노드에 BestEffort로 Pod을 띄우려고 한다.
그런데 이제 문제가 발생한다. 새롭게 들어온 Pod은 자신이 얼마나 resource를 사용할 수 있을지 명시를 하지 않았기 때문에 해당 Pod이 resource를 어디까지 사용할 수 있는지 Kubernetes는 알지 못하고 해당 Pod은 자신이 필요한대로 무한정으로 node의 resource를 추가적으로 요구하고 사용하게 된다.
그 결과 기존에 떠 있던 Pod들을 resource starvation 상태로 만든다. 이것뿐만이면 그나마 다행이지만 더 문제가 심해지면 Kubernetes를 동작할 수 있게 해주는 kubelet과 같은 중요한 서비스들도 resource가 부족해져 제대로 동작할 수 없는 문제가 발생하기도 한다. 이쯤 되면 전체 Kubernetes 클러스터가 이미 망가진 상태이다.
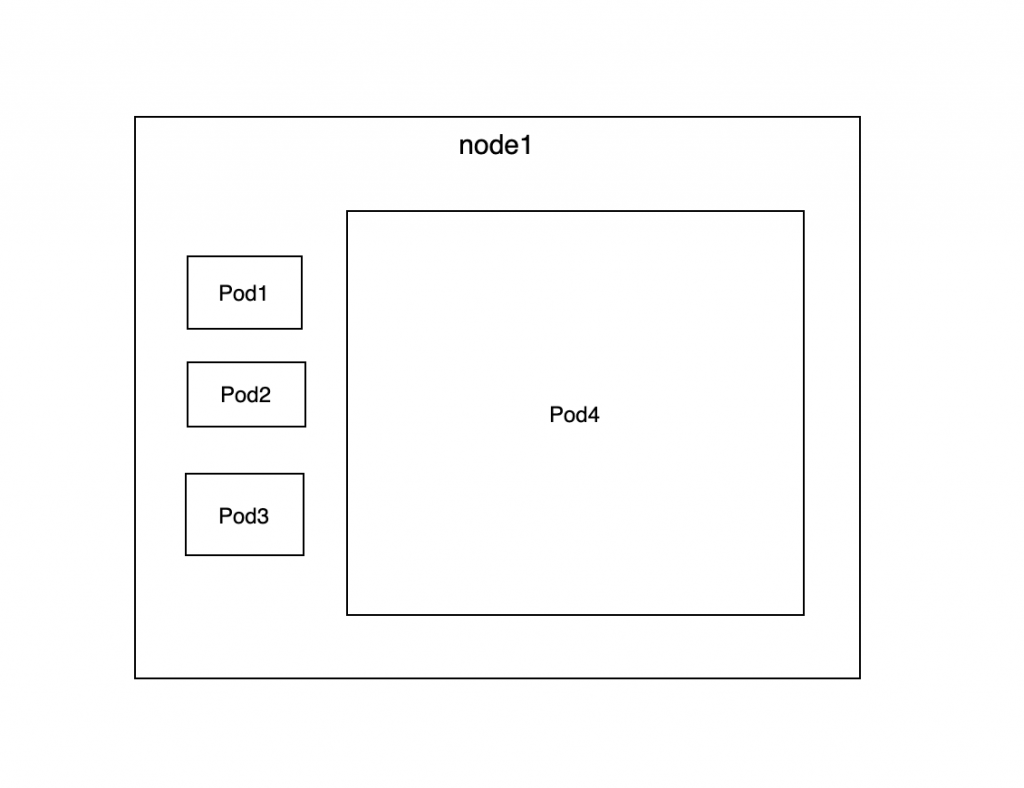
BestEffort 서비스는 띄우지 말자.
결론적으로 BestEffort 서비스는 띄우지 않는 것이 가장 좋다. 어떤 Pod은 아주 작아서 문제를 일으키지 않을 수도 있지만 그렇다면 차라리 아주 작은 resource request, limit 값을 할당해주는 것이 좋다.
Burstable
Burstable QoS는 request, limit resource 값을 설정했지만 limit 값이 request 값보다 높을 때 설정된다. 이는 어떤 서비스가 피크 타임이 존재해서 특정 시간동안 더 많은 resource를 쓰게하고 싶다거나 어플리케이션이 최초 부팅시 더 많은 resource를 필요로 한다거나 할 때 유용하게 사용할 수 있다.
Burstable은 BestEffort보다 resource starvation 문제를 줄일 수는 있지만 완전히 없어지는 것은 아니다. 위에서 말했듯이 기본적으로 Pod이 node에 스케쥴링될 때에는 resource request을 통해서 스케쥴링되기 때문에 어떤 서비스가 트래픽 피크 타임 때 더 많은 resource를 사용한다면 다른 서비스가 사용해야할 resource를 잡아먹을 수도 있다.
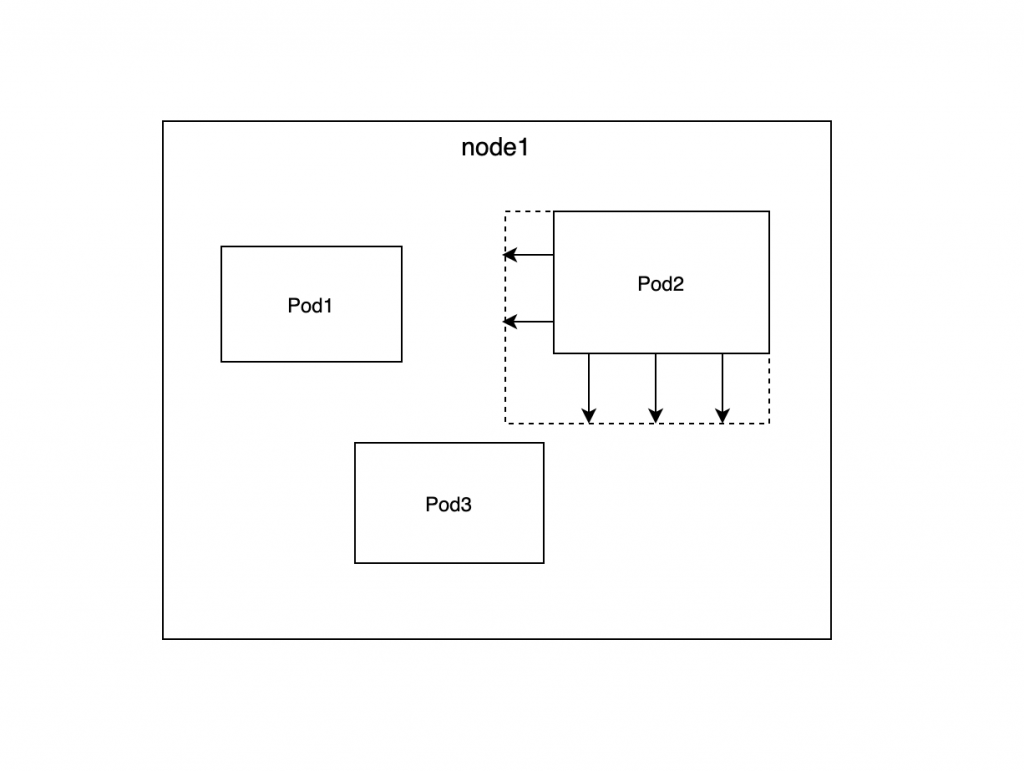
문제가 될 수 있는 상황은 이제 하나의 Pod만 순간적으로 resource를 더 많이 쓰면 별로 상관이 없다. 하지만 어떤 특별한 이벤트 때문에 동시다발적으로 여러 Pod들이 resource request 값을 넘어서 limit 값까지 사용한다고 했을 때 이제 문제가 발생할 수 있다.
노드의 남은 resource는 없어지게 될 것이고 다른 서비스들의 resource starvation 문제를 발생시킬 수 있고 위에서 BestEffort의 문제 상황이 똑같이 연출될 수 있다.
하지만 Burstable은 상황에 따라 경제적인 선택이 될 수도 있다.
어떤 서비스는 평상시에는 resource를 별로 안잡아먹다가 특정 피크 시간에만 resource를 많이 먹을 수도 있다. 이런 경우 최악의 상황에 대비해서 평상시에도 많은 resource를 할당 받고 있다면 해당 노드에 다른 서비스들을 띄울 수가 없고 새로운 node를 사서 하나 더 띄워야할 수도 있다. Compute Engine 값이 스펙에 따라서 만만치 않다는 것을 생각하면 이는 경제적 손실로 이어질 수 있다.
잠깐 동안 많은 resource를 먹고 금방 다시 원래대로 돌아온다면 Burstable은 나쁘지 않은 선택일 수도 있다. 하지만 resource를 많이 먹는 동안 다른 서비스들이 사용할 resource를 사용할 수 있다는 점을 감안하자.
Guranteed
Guranteed QoS는 request, limit resource 값을 설정했고 limit 값이 request 값이 같을 때 설정된다. 가장 경제적 비용이 크지만 가장 안정적으로 서비스를 운영할 수 있는 방법이다. request, limit 값이 같기 때문에 피크 타임 때도 어떤 서비스가 최대 얼마만큼 resource를 사용할지에 대한 정확한 예측이 가능하다. 또한 다른 서비스의 resource starvation 문제도 완전히 없애준다.
한 가지 주의해야할 점이 있다면 Kubernetes 컨텍스트 바깥에서 동작하는 서비스의 resource는 고려되지 않는 다는 것이다. 어떤 말이냐면 Compute Engine 자체에서 돌고 있는 모니터링 툴이라던가 native하게 돌고 있는 프로그램이 사용하는 resource 자원은 Kubernetes 클러스터 단에서 알 수가 없다.