memory leak 원인 찾기 - 어플리케이션이 가지는 상태를 생각하자
이 글은 어떤 글인가요?
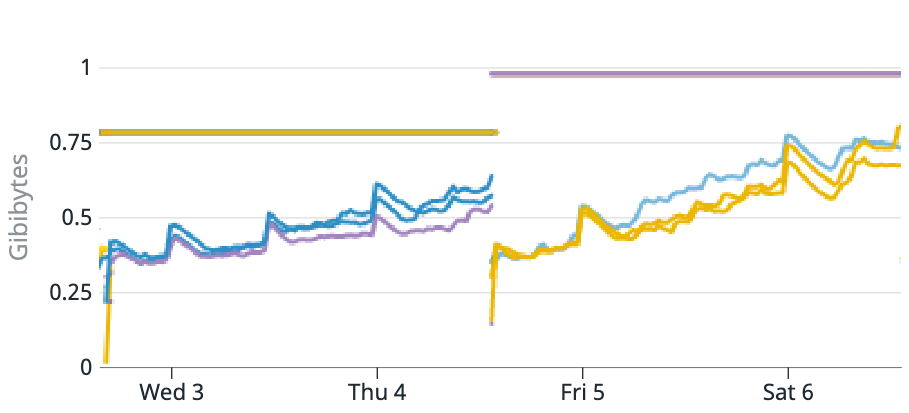
최근에 어떤 서비스에서 메모리 사용량이 지속적으로 증가했고 모니터링 알람으로 그 사실을 알게되었다. 이번 포스팅에서는 어떻게 memory leak 문제를 해결했는지 그 과정을 기록으로 남기고 싶어 정리해보고자 한다.
어느날 갑자기 어떤 서비스의 메모리 사용량이 높다고 알람이 왔다. 그래프 추세를 보았을 때 느낌이 좋진 않았지만 다른 일을 우선 순위를 높여 처리하고 있었기 때문에 우선 메모리를 좀 더 주고서 다시 한 번 기다려보기로 했다. 그리고 며칠이 지나서 다시 알람이 울렸을 때 조용히 백로그 카드를 만들어 올리게 되었다.
대조군 설정 - Canary 서비스
우선은 서비스에 기능이 제대로 동작하지 않는 버그가 있는 것은 아니었다. 그리고 최대한 프로덕션 환경의 트래픽을 서비스가 받았을 때 비교가 가장 잘 될 것이라고 생각했다. 그리고 또 중요한 것 고려 사항 중 하나가 메모리 증가의 원인으로 가장 첫 번째로 의심했던 것이 Docker base 이미지였기 때문에 코드 변경이 없을 것이라 생각했다. 그래서 이것 저것 코드를 바꿔서 배포하다가 버그가 숨어들어간 코드가 서비스될 일은 없을 것이라 생각했다.
대조군을 만들기 위해서 생각한 것이 Canary 서비스를 두는 것이었다. Canary는 원래 Canary 배포 전략에서 많이 등장한다. 이 전략은 광산에 광부들이 들어갈 때 안에 유독가스가 있는지 여부를 확인하기 위해 카나리아라는 새를 먼저 보내보는 것에서 유래했다.
그래서 Canary 배포는 새로운 서비스를 기존 서비스와 같이 트래픽을 로드밸런서가 분산을 시켜주는데 중요한 것은 새로운 서비스는 적은 트래픽을 받게 된다. 그래서 만약 새로운 서비스에 문제가 있더라도 error rate이 전체 서비스를 업데이트했을 때에 비해서 낮게 나온다. 이는 SLO 달성에 큰 도움을 준다. 혹시 Canary 배포와 SLO 관계에 대해서 관심이 있다면 이 글을 읽어 봐도 좋다.
그런데 Canary 개념을 꼭 배포 때 쓰란 법은 없다. 중요한 것은 실제 프로덕션 환경 트래픽을 받아볼 수 있고 혹시 (그러면 안되겠지만) 터지더라도 위험 부담이 조금 덜하다. 또한 필요에 따라 부하를 얼마나 줄지도 편하게 바꿀 수 있다. 첫 단락에서 말한 전제 조건에서는 정말 좋은 테스트 환경이 된다.
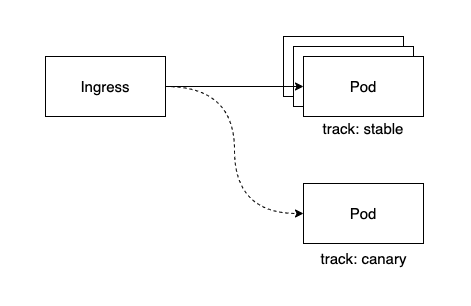
현재 서비스는 Kubernetes 환경에서 운영되고 있기 때문에 Service의 pod selector를 활용해서 비교적 간단하게 Canary를 만들어 볼 수 있다. track: stable 레이블이 붙은 서비스는 기존에 운영되고 있던 서비스들을 나타낸다. 그리고 track: canary 레이블이 붙은 서비스는 테스트를 위해 배포된 서비스이다. 보통 stateless한 서비스라면 Deployment를 통해 Pod을 관리하게 되는데 운영 서비스를 위한 Deployment와 테스트를 하기 위한 Canary Deployment의 replicas를 조정해가면서 각각에 트래픽을 얼마나 줄지를 결정할 수 있다.
JVM Heap Profiler - MAT
JVM을 위한 Docker 이미지가 문제인가 하여 여러 시도를 해보았지만 Docker 이미지 문제는 아닌 것 같았다. 이제 어플리케이션의 memory leak을 의심하였다. JVM 기반의 어플리케이션의 heap 메모리를 볼 수 있게 도와주는 도구는 여러가지가 있다. 그 중에서 이번에 사용했던 것은 Eclipse Memory Analyzer(MAT)인데 주로 사용법과 관련된 내용이 대부분일 것 같아서 조금만 적도록 해야겠다.
MAT은 어플리케이션의 heap 메모리를 dump하여 heapdump 파일을 MAT이 읽어들이고 그것을 통해 현재 어떤 객체가 메모리 사용량이 높은지, memory leak 의심되는 부분은 어디인지에 대해서 분석해서 알려준다.
그래서 먼저 Kubernetes에서 서비스되고 있는 Pod의 프로세스에서 heapdump를 가져와야한다. heapdump를 가져오기 위해 사용할 도구는 jmap이다. 그런데 아쉽게도 현재 base docker 이미지를 OpenJDK alpine을 쓰고 있었고 여기서는 jmap의 dump 기능이 제대로 동작하지 않는다.
Base docker 이미지가 memory leak에 영향을 주지 않을 것이라 생각했기 때문에 canary 서비스에 대해서만 OpenJDK debian 이미지를 가져와서 새로 배포하였다. 그리고 아래의 명령어를 이용하여 heapdump 파일을 생성하고 로컬로 가져온다.
# jmap -dump를 이용하여 어플리케이션의 heapdump 파일을 생성한다. PID는 Pod 내에서 실행되는
# 어플리케이션은 루트 프로세스로 돌기 때문에 PID는 1이다.
kubectl exec -it <pod-name> -- jmap -dump:format=b,file=heapdump.hprof 1 && \
# kubectl cp를 이용하여 로컬 컴퓨터로 heapdump 파일을 전송한다.
kubectl cp <namespace>/<pod-name>:/heapdump.hprof ~/heapdump.hprofMAT에 대한 더 자세한 설명은 생략한다. 중요한 것은 이 방법으로도 정확한 원인을 파악할 수 없었단 것이다. 메모리 프로파일링 결과 특정 객체가 엄청나게 메모리를 사용하고 있다고 표시가 제대로 안되어있었고 기본적으로 제공되는 의심되는 memory leak 리스트에도 눈에 띄는 의심 포인트들이 보이지는 않았다.
memory leak 은 기본적으로 어떤 경우에 발생하는가?
여기까지 와서 어떤 제대로 된 단서를 찾지 못해 조금 힘이 빠진 상태였다. 그리고 조금 쉬었다가 memory leak이 발생할 수 있는 이유에 대해서 다시 생각해보았다.
memory leak은 결국 어플리케이션이 할당 받은 heap 메모리에 어떤 객체(데이터, 값 어떻게 부르든 간에...)를 계속 저장해두는데 GC(Garbage Collector)가 이를 dereference를 하지 못하였고 시간이 지날 수록 어플리케이션이 사용하는 heap 메모리의 사이즈가 커지는 현상을 말한다. 왜 GC가 heap 메모리에 있는 데이터를 dereference를 하지 못하는가는 어플리케이션이 계속 해당 데이터를 가지고 있기 때문이다.
여기까지 생각하니 이제 해당 어플리케이션이 가질 수 있는 상태가 어떤 것들이 있는지를 생각해보게 되었다. 어플리케이션의 상태가 곧 어플리케이션이 가지고 있는 데이터이고 이것은 heap 메모리 영역에 담긴다. 다시 말하면 memory leak의 범인이 될 수 있는 좋은 후보들이다.
memory leak 범인은 바로.. Histogram metric?
문제 해결의 실마리는 반짝하면서 찾아왔다. 서비스의 상태와 관련된 여러 부분들을 살펴보던 중 메트릭을 export하는 API를 보았고 여기서 제공되는 메트릭의 목록을 살펴보니 그 갯수가 8천개가 넘었다. 그리고 다시 서비스를 껐다 켰을 때 동일한 API에서 제공되는 메트릭 목록은 100개 언저리였다.
메트릭도 서비스에서 관리하는 상태 중 하나이다. 그리고 보통 하나의 메트릭에 여러 개의 태그가 달리고 각각의 태그와 메트릭 조합에 대해서 값이 저장된다. 그리고 이것 하나 하나가 메모리 자원에 해당된다. 문제가 되었던 메트릭의 type은 histogram 타입이었다. 보통 histogram 타입의 메트릭은 다양한 용도로 쓰일 수 있지만 percentile 함수를 쓰기에 적합한 메트릭이다. histogram 타입의 메트릭을 이용하여 서비스 latency의 p95, p99 값을 구할 수 있다.
Prometheus의 histogram metric에 대한 설명은 여기에 잘 나와있다. Prometheus는 histogram을 _bucket 접두사가 붙은 메트릭을 통해 관리한다. 이와 관련된 설명도 이전 링크에 잘 나와있으니 참고하면 좋을 것 같다. 문제는 이 bucket이 메트릭의 태그별로 끊임없이 늘어났고 이것이 결국 memory leak을 초래했다. 어플리케이션의 메트릭은 계속 관리해야하니 이와 관련된 데이터가 dereference가 되지 않았던 것이다.
마지막으로 남은 의문은 저 bucket이 어떻게 생성되냐는 것이다. 저것을 조절할 수 있으면 이제 histogram 타입의 메트릭을 쓰더라도 큰 부담이 되지 않을 수 있다. 이 부분은 더 자세히 찾아보지 않았다. bucket이 생성되는 원인에 대해서 좀 더 알고 싶으면 이 위키 의 Number of bins and width 부분을 읽으면 힌트를 얻을 수 있을 것 같다. 이제 원리를 어느정도 이해하면 Prometheus histogram metric을 찍을 때 이 문서를 보면서 해답을 얻을 수 있을 것 같다.
마무리하며
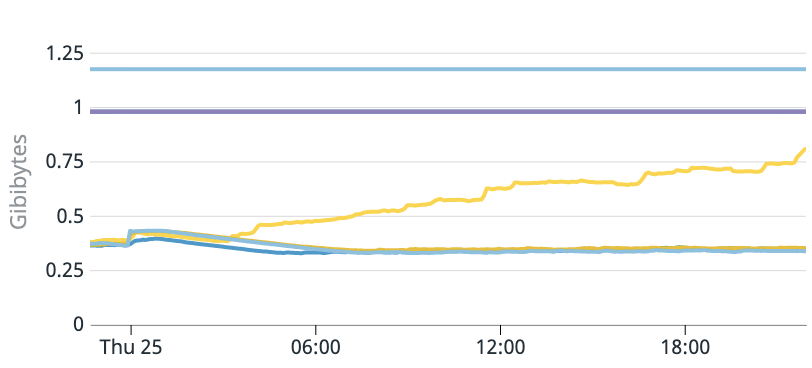
결국 이 문제는 Prometheus histogram metric과 관련된 모듈을 사용하지 않기로 결정하면서 해결되었다. Prometheus histogram metric 때문이라는 강한 확신이 있었고 코드 수정은 없이 설정 파일만 수정하면 되었기 때문에 바로 프로덕션으로 배포하고 카나리 서비스와 메모리 사용량을 비교해보았다. 저 노란선만 올라가는 모습을 보면서 너무 기뻤던 기억이 난다.