Terraform CI/CD 파이프라인 구축과 운영 기록
Updated
이 포스팅의 내용으로 HashiTalk 2021에 'Terraform 도입과 CI/CD 파이프라인 구축 및 운영' 라는 제목으로 발표를 했다. 자세한 내용은 여기서 살펴볼 수 있다.
2주 간의 시간이 주어지고 현 상황을 돌아보았다.
1분기가 끝나갈 무렵 스프린트가 끝나고 잠깐 2주 정도 각 팀이 자유롭게 쌓여 있던 기술 부채 처리나 이전 스프린트에서 구현하지 못한 기능들을 마무리할 수 있는 시간이 생겼다. 이 시간 동안 어떤 것을 해야 가장 효과적이고 다음 분기에 DevOps 팀이 편할 수 있을까라는 고민을 했다. 그 당시 상황은 새로 생겨나는 프로젝트를 Terraform 으로 인프라 리소스를 관리하기 시작했었고 다른 팀원이 잠깐 군대 훈련소에 가 있는 상황이라 그 분이 돌아왔을 때 효과적으로 리뷰와 협업을 할 수 있는 환경이 마련되면 좋겠다고 생각했다.
그 분이 없는 동안은 혼자 일을 하는 상황이라 자유롭게 Terraform을 수정하고 필요할 때 혼자서 적용하면 되었다. 그리고 그 인프라 상태에 대한 파일도 git에서 관리되고 있었다.
이러한 상황에서 다른 사람이 들어와서 같이 일을 했을 때 같이 일을 하는 사람들이 엄청난 고통이 될 것이라고 생각했다. 왜냐하면
첫 번째 문제는 git에서 관리되고 있는 인프라 상태 파일이었다. 이것을 처음으로 문제라고 느꼈던 상황이 서비스 초기 구축 당시 있었다. 그 때 당시 'Terraform에 대한 지식이 거의 없는 관리자'분과 화상 통화를 하며 인프라 구축을 했었는데 내가 그 분께 명령어를 알려주고 그 분이 직접 타이핑을 해서 배포를 하는 방식이었다. 그런데 그 분 로컬에 있는 인프라 상태 파일과 내 로컬에 있는 인프라 상태 파일이 달라서 꽤 고통을 받았다. 안그래도 서로의 리소스가 많이 없는 상태인데 이 문제 때문에 시간을 꽤 많이 잡아먹었고, 스스로도 배포에 대한 자신감이 떨어졌다. 그래서 누군가와 협업을 했을 때에도 위와 같은 문제가 빈번하게 발생할 것 같았고 이를 해결해야 원만하게 일을 진행할 수 있을 것 같았다.
두 번째 문제는 현 상태가 누군가와 같이 원만하게 협업을 할 수 있는 환경이 아니라는 것이다. Terraform을 처음에 쓰기로 결정한 이유가 혼자 일을 할 때에는 콘솔에서 여러 화면의 여러 뎁스(depth)를 타고 들어가서 인프라 리소스를 파악하는 것이 아니라 선언적으로 작성된 Terraform 코드를 보며 현재 인프라 리소스에 대한 파악을 쉽게 하고, 이슈가 발생하거나 변경이 필요할 때 그 대처를 좀 더 편하게 하고자 하기 위함이었고, 여러 사람이 일을 할 때에는 서로가 변경하는 코드를 git을 통해서 리뷰를 하고 어떤 것이 변경되는지 파악할 수 있고, 충돌 없이 병합하고, 그리고 최종적으로 합의된 상태를 인프라에 배포할 수 있지 않을까라는 기대감 때문이었다. 그런데 지금은 팀원이 작업한 변경 사항이 어떤 영향을 미칠지 확인할 수 있는 방법이 있지만 매우 불편한 상태이고 그렇기 때문에 리뷰가 어렵다. 비효율적이고 느리다.
그 당시의 나는 위의 문제가 앞으로 일을 어렵게, 그리고 진행되는 속도를 느리게 만들 수 있는 큰 장애물이라고 생각했고 2주 동안 위 문제를 해결하기 위해서 어떻게 현재 상태를 개선시킬 수 있는지에 대해서 찾아보고 생각했다. 그래서 아래와 같은 목표들이 생겼다.
- 인프라 상태를 글로벌하게 실시간으로 공유할 수 있게 만들자.
- 팀원간에 서로 리뷰를 할 수 있는 구조를 만들자.
- 자신있게 배포할 수 있는 구조를 만들자.
인프라 상태를 실시간으로 공유할 수 있으면 좋겠다.
중요한 목표 중 하나인데 팀원 서로가 개발 환경에서 테스트를 하거나 개발을 할 때 실시간으로 최신 상태를 알고 있어야 자신이 제대로 테스트를 했는지를 확신할 수 있고 미리 중간에 이상하다면 팀원에게 공유하여 서로가 어떤 테스트 중인지를 알 수 있고 이를 인지하며 개발을 진행할 수 있다.
다행히 이는 비교적 간단하게 해결할 수 있었는데 Terraform의 상태를 저장하는 클라우드 스토리지를 사용하여 누군가가 테스트 중에 terraform apply 를 했을 때 이 상태가 곧바로 스토리지 데이터에 반영되어 다른 사람들이 이 변경된 상태를 실시간으로 볼 수 있었다. 그래서 첫 번째 문제는 이렇게 해결하자고 생각하고 다음으로 넘어갔다.
방법에 대해서는 아래 링크에 자세히 설명되어 있어 읽어보고 쉽게 적용해볼 수 있다. 물론 쉽게 적용하는 것이랑 좋은 구조를 가져가는 것은 별개의 이야기이다.
https://www.terraform.io/docs/language/settings/backends/configuration.html
서로 작업물에 대해서 리뷰를 할 수 있는 환경이면 좋겠다.
Terraform을 이용하여 코드로 인프라의 설정을 관리할 수 있었기 때문에 PR을 이용하여 서로의 작업물을 리뷰하고 머지하는 과정을 생각했다. 그리고 GitOps라는 개념에서 힌트를 얻어 PR을 날릴 경우 해당 PR이 해당 환경에 어떤 영향을 미치는지 사전에 보여주고 해당 PR이 머지가 되었을 때 해당 변경 사항이 실제로 반영된다는 아이디어에서 출발했다.
그리고 여기서 자연스럽게 어떤 브랜치에 머지할 것인지 브랜치 전략에 대한 것과 이 머지된 코드가 어떻게 배포될 것인지 배포 전략에 대한 고민으로 이어졌다.
현재 Terraform 코드의 디렉토리 구조를 살펴보면 모든 프로젝트별 환경별로 구분되는 모듈이 존재하는 부분도 있었고 전체 프로젝트에서 공통적으로 쓰이는 공통 모듈도 존재했다. 이는 코드가 변경되었을 때 적용되는 범위가 모두 다르다. 환경별로 적용되는 모듈들은 변경되었을 때 해당 환경에만 변경 사항이 전파되지만 공통 모듈이 변경되었을 때에는 전체 환경에 해당 변화가 전파된다.
그리고 Terraform 코드는 프로젝트(project), 네트워크(network), 워크로드(workload) 라는 총 세 개의 레이어로 구분되어 관리되고 있었다. 프로젝트 레이어에서는 특정 프로젝트 범위에서의 설정들 예를 들어 해당 프로젝트에서는 어떤 서비스를 사용할 것인지, IAM 정책 등이 관리되고 있었고 네트워크 레이어에서는 VPC, Route, IP, NAT, Firewall 등 네트워크와 관련된 리소스들이 관리되고 있었고 마지막으로 워크로드 레이어에서는 Kubernetes, Storage, KMS 등의 리소스들이 관리되고 있었다.
아래의 구조는 위에서 설명한 파이프라인을 구축하기 전의 간략하게 정리한 디렉토리 구조이다.
.
├── projects
│ ├── common
│ ├── project-X
│ ├── project-Y
│ ├── modules
├── networks
│ ├── common
│ ├── project-X
│ │ ├── development
│ │ ├── production
│ │ └── qa
│ └── project-Y
└── workloads
├── project-X
│ ├── development
│ ├── production
│ └── qa
└── project-Y위의 구조에서 common과 project-X의 환경별 모듈의 배포 라이프사이클은 달라야한다. 왜냐하면 전에 설명했듯 서로 배포되었을 때 영향을 주는 범위가 다르기 때문이다. 다음으로 생각했던 것은 프로젝트 레이어의 설정들이 파이프라인을 태우는 것이 적합한가에 대한 것이다. 왜냐하면 여기에는 IAM 설정과 같은 것이 포함되어 있는데 이는 아직 프로젝트 초기 단계여서 가능한 것이었고 이 부분은 앞으로 다른 사람에게 권한을 넘기고 엔지니어가 수정을 할 수 있으면 안된다고 생각했다. 그래서 프로젝트 레이어는 CI/CD 대상에서 제외되었다.
소프트웨어 CI/CD 파이프라인과 달리 배포 라이프사이클이 다른 부분이 존재했고 환경별(development, qa, production)로 설정 파일이 100% 일치할 것이라는 확신이 없었기 때문에 git tag를 이용해서 버전을 구분하기가 어려울 것이라고 생각했다. 그래서 환경별로 브랜치(branch)를 구분하여 설정을 관리를 하기로 했다.
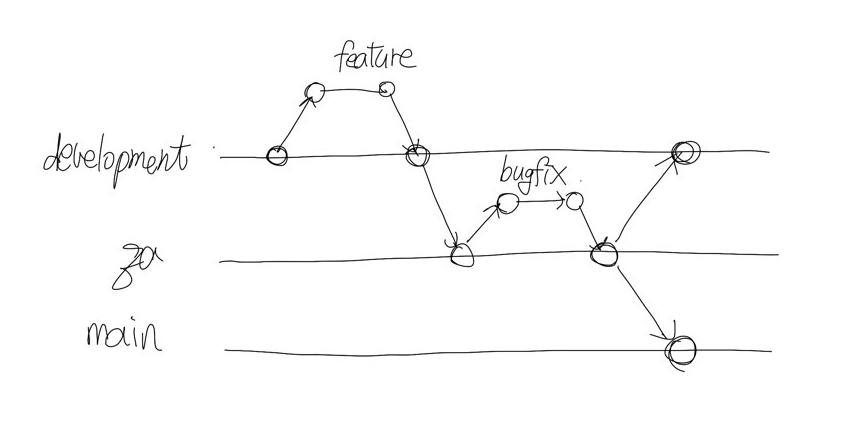
PR을 만들 때 CI 과정이 진행되면서 코드 포맷팅, 린트 그리고 terraform plan 이 돌아가고 이 PR을 통해서 개발 환경에 어떤 변경이 생길지를 보여준다. 그렇기 때문에 DevOps 팀원은 PR을 리뷰할 때 Terraform 코드, 컨벤션뿐만 아니라 CI 과정에서 돌아가는 terraform plan 결과물을 꼭 리뷰해야한다. 만약 terraform plan 의 변경사항이 이상하다면 이 부분에 대해서는 코멘트를 달고 수정을 요청해야한다.
그래서 한 스프린트 동안 진행되는 새로운 설정 변경에 대한 코드들은 기본적으로 development 브랜치에 머지된다. 그리고 머지될 때마다 해당 변경사항이 terraform apply 를 통해서 개발 환경에 배포된다. 이렇게 한 스프린트 동안 진행하는 새로운 피쳐, 변경사항은 모두 development 브랜치에 쌓이고 개발 환경이 변경 된다.
그리고 스프린트가 끝나기 3-5일 전에 'development'에 쌓인 커밋들을 'qa' 브랜치로 머지하는데 이 때도 마찬가지로 CI 과정에서 terraform plan 을 통해서 변경사항들을 볼 수 있다. 그리고 이 변경사항들을 같이 살펴보며 리뷰를 한다. 그리고 이상이 있다면 추가적인 커밋을 통해서 해당 이슈를 해결한다. 이렇게 전부 'Approve'가 되면 'development' 브랜치에서 'qa' 브랜치로 머지를 한다.
해당 변경사항들이 QA 환경에 적용되면 QA 과정을 거친다. 여기서 이슈나 버그가 발견된다면 이슈 종류에 따라 이슈 픽스에 대한 커밋이 'development'에서부터 내려오기도 하고 'qa' 브랜치 내에서 수정이 되기도 한다. 최종적으로 이슈가 없다고 판단되면 'main' 브랜치에 머지를 하고 '관리자'가 해당 변경사항을 GUI를 통해 배포하게 된다.
프로덕션의 경우 CD 과정을 통해서 배포되도록 자동화하지 않았다. 프로덕션의 경우 시크릿과 같은 중요한 정보가 있기 때문에 관리자만 배포할 수 있고 배포하기 전에는 'qa' 브랜치에 머지할 때와 마찬가지로 관리자가 plan 결과물을 공유해주고 여기서 Approve가 되면 프로덕션 배포가 진행된다.
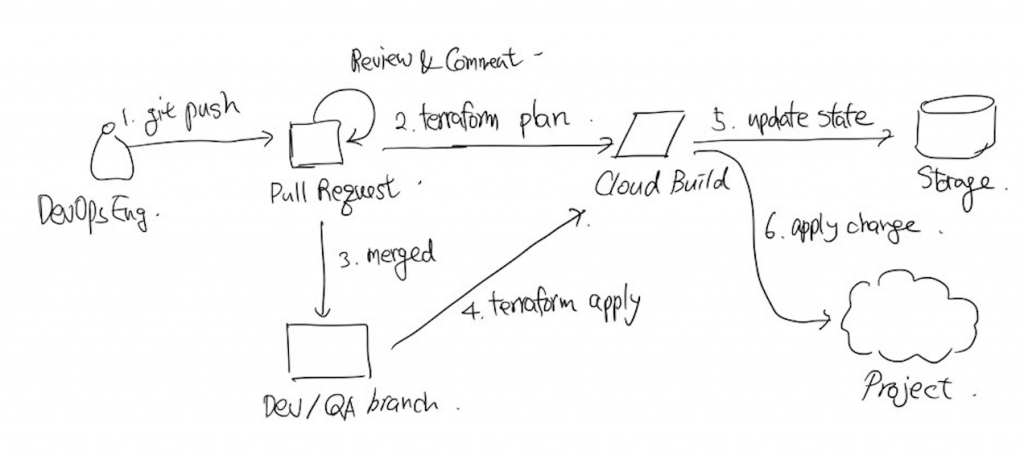
구체적인 방법에 대해서는 아래 링크에서 충분히 힌트를 얻을 수 있을 것 같다. 방법 자체는 복잡한 것이 아니지만 각자 상황에 맞게 프로세스나 정책적인 부분을 어떻게 가져갈지에 대해서 고민하는 것이 더 어려운 부분인 것 같다.
https://cloud.google.com/architecture/managing-infrastructure-as-code
쉽고 자신있게 배포하고 싶다.
자신있게 배포하기 위해서는 충분히 테스트한 설정들이 그대로 Dev에서 QA로, 그리고 QA에서 Production으로 넘어가야 한다. 그러기 위해서는 각 스테이지에서 변경되는 코드들이 최소화가 되어야 하는데 기존의 코드에서는 다음과 같은 문제점이 있었다.
예를 들어 다음과 같은 네트워크 설정이 Project-X 개발 환경에서 반영되어 충분히 테스트 되었다. 그래서 이제 이 설정들을 QA 환경에 배포해야한다고 하면 'networks/project-X/development/main.tf' 에 있던 코드들을 'networks/project-X/qa/main.tf' 로 옮기고 PR을 만들고 리뷰 후에 머지해야 한다.
resource "google_compute_network" "main" {
name = local.main_vpc_name
project = local.project_id
auto_create_subnetworks = false
}
resource "google_compute_subnetwork" "main" {
name = local.main_subnet_name
project = local.project_id
ip_cidr_range = "..."
network = google_compute_network.main.self_link
region = var.region
private_ip_google_access = true
}
resource "google_compute_firewall" "ssh" {
project = local.project_id
name = "..."
network = google_compute_network.main.name
direction = "INGRESS"
source_ranges = ["..."]
allow {
protocol = "tcp"
ports = ["22"]
}
target_tags = ["..."]
}그런데 지금은 네트워크 구성이 단순하고 컴포넌트가 적어서 변경사항들을 그대로 스테이지마다 반영시켜주는게 쉽지만 시간이 지나서 컴포넌트가 많아지고 복잡도가 올라간다면 실수가 발생할 가능성이 다분하다. 그리고 잘못되었다면 어떤 것이 잘못되었는지 쉽게 발견하기도 어려울 것이다.
그래서 개발, QA, 프로덕션에서 공통으로 쓰이는 컴포넌트들을 묶어 base라는 모듈로 만들고 이 모듈을 각 환경에서 사용하기로 한다.
resource "google_compute_network" "main" {
name = var.main_vpc_name
project = var.project_id
auto_create_subnetworks = false
}
resource "google_compute_subnetwork" "main" {
name = var.main_subnet_name
project = var.project_id
ip_cidr_range = "..."
network = google_compute_network.main.self_link
region = var.region
private_ip_google_access = true
}
resource "google_compute_firewall" "ssh" {
project = var.project_id
name = "..."
network = google_compute_network.main.name
direction = "INGRESS"
source_ranges = ["..."]
allow {
protocol = "tcp"
ports = ["22"]
}
target_tags = ["..."]
}module "base" {
source = "../base"
project_id = local.base_project_id
environment_code = local.environment_code
region = var.region
main_vpc_name = local.vpc_name
main_subnet_name = local.vpc_subnet_name
}사실 코드적으로 봤을 때 재사용되는 코드들을 컴포넌트로 빼는 단순한 작업인데 배포 파이프라인을 구축하기 이전에는 반복되는 코드들의 문제점을 심각하게 느끼지는 못했다. 하지만 배포 파이프라인을 구축하면서는 '배포'라는 작업의 특성때문에 인프라의 설정이 최대한 그대로 다음 스테이지로 옮겨가는 것이 매우 중요했고 이러한 포인트 때문에 공통 모듈을 묶게 되었다.
이제 모듈 내부에서 복잡한 연산이 일어나지 않는 한 개발 환경에서 테스트된 컴포넌트들과 그 컴포넌트들간의 관계가 그대로 다음 스테이지로 넘어갈 수 있다는 확신이 생겼다.
파이프라인 운영과 이슈
파이프라인을 구축하고 나서 2개의 스프린트가 지나가고 있다. 사실 파이프라인을 만들면서도 처음에 생각했던 문제점들이 제대로 해결되지 않으면 어떡하지라는 불안감이 계속 들었다.
좀 더 시간이 지나고 구축한 파이프라인 사용에 대한 경험이 쌓이면 이 섹션을 업데이트 해보면 좋겠다는 생각이 든다. 파이프라인을 구축하고 나서 현재까지 사용을 보면 꽤 많은 수의 개발 환경 배포, 두 번의 QA 환경 배포가 있었다.
사용 패턴을 살펴보면 개발 환경에서는 빠르게 테스트를 해보기위해 로컬에서 apply를 하는 경우가 꽤 잦았다. 그래서 이 때 다른 사람은 테스트를 하는 사람의 코드가 로컬에 없기 때문에 개발 환경에 코드가 머지될 때 리뷰 과정에서 테스트 환경이 날아갈 것이라고 커뮤니케이션을 하고 머지를 하기도 했다. 개발 브랜치에서 QA 브랜치로 머지할 때는 plan 목록을 쭉 읽어보며 잘못된 부분이 없는지 꼼꼼히 집중해서 살펴보았다. 그 결과 다행히 큰 이슈는 존재하지 않았다.
파이프라인 동작과 관련해서는 한 번씩 인프라 상태를 저장하는 스토리지에서 여러 사람이 같은 파일을 동시에 업데이트하는 것을 막기 위한 .lock 파일이 있는데 이것이 가끔 한번씩 삭제되지 않아서 CI/CD 과정 중에 알고보면 올바르게 동작하는데도 실패했다는 메세지가 뜰 때도 있었다. 이 때는 보통 재시도를 하면 정상적으로 동작하였다.
돌아보며..
사실 글을 쓰는 순간에도 문제에 대한 정의가 제대로 되었나? 좀 더 간단한 방법이 있지 않을까? 라는 의구심이 들었다. 일단은 구축했던 사실에 집중해서 정리를 해보았고 프로세스가 복잡하다거나 더 좋은 간단한 방법이 생각나거나 누군가 제안을 해준다면 같이 개선해볼 것 같다.